人Co INTERNSHIP 2016 하계 프로그램을 마치며
- Posted at 2016/09/07 14:31
- Filed under 회사소식
한국폴리텍대학 임지희
Bioinformatics를 배우기 위해 짧은 시간
동안 다양한 곳에서 여러 경험을 해 본 저에게 人CoINTERNSHIP은 한 걸음 나아갈 수 있는 발판이었습니다. 그러므로 앞으로
이 분야에 대해 신중하게 생각하고 조금 더 가까워지고 싶으신 분들에게 꼭 추천하고 싶은 교육입니다. 각 관심 분야에만 빠지기
십상인 경우가 부지기수인데요. (주)인실리코젠에서 진행된 人CoINTERNSHIP은 교육과 인성이 함께 어우러지는 보기 드문 전문
교육이었습니다. 한 달 동안의 교육이지만 소속감을 충분히 느낄 수 있었고, 적극적인 자세를 통해 바로 피드백 받을 수 있는 좋은
환경 조건을 느낄 수 있었습니다. BI 교육과 업무 그리고 실습을 동시에 경험할 수 있으며, 비록 짧은 시간이지만 주어진 시간
동안 최선의 것을 배웠습니다. 회사에 계시는 분들 모두 멘토가 되어 선뜻 손 내밀어 주셨습니다. 그러므로 따뜻함을 느낄 수
있었고, 훈훈한 마음으로 교육받을 수 있었습니다. 그리고 함께한 인턴분들 덕분에 서로 의지하며 어려운 부분도 즐겁게 해낼 수
있었습니다.
앞으로 이곳에서의 한 달은 잊혀지지 않는 추억이자
진행형이 될 것입니다. 바쁘신 업무 중에도 신경 써 주시고 배려해 주셔서 감사드립니다. 그리고 이런 자리를 만들어 주신 최남우
대표님과 함께 이끌어주신 이사님들 그리고 선임님, 주임님, 선배님들 모두 감사드립니다. 좋은 가르침을 마음속 깊이 새기고 그
기운을 받아 어느 곳에서 Bioinformatics를 하던 기운을 불어넣을 수 있는 사람이 되도록 하겠습니다.
1년 중에 가장 더운 7월 한 달 동안 수고 많으셨습니다. 아마도 중복에 식당에서 전 직원분들과 함께 삼계탕 먹은 날은 잊지 못할 것입니다. 아무쪼록 건강하시고 행복하시길 바랍니다. 감사합니다.
한국폴리텍대학 신훈재

식품학 전공으로 식품회사에서 일하다 폴리텍대학을
통하여 생명 정보학을 처음 접하게 되었습니다. 1학기가 끝난 뒤 실무 적응 실습을 수행했어야 했는데, 人CoINTERNSHIP을 지원하여 약
1달 동안 (주)인실리코젠에서 함께 할 기회를 얻게 되었습니다.
人CoINTERNSHIP 커리큘럼은 매우 다양하고 잘
되어있습니다. 3일차까지는 회사 및 사회생활을 할 때 필요한 것들을 알려주시는데 매우 상식적인 내용이고 쉽게 쉽게 상황별로
이야기해주셔서 이해가 잘 되었습니다. 공통교육을 받으면서 인상 깊었던 부분이 3가지가 있었는데 첫 번째는 人CoDOM 이었습니다. 위키를
기반으로 만들어져 있고 Bio 분야에 관련된 정보들이 다양하여 배우는 사람 관점의 자료가 다양해서 매우 좋았습니다. 두 번째는 정은미
이사님께서 하셨던 말씀인데, 직원이지만 리더의 마음가짐으로 일하라고 말씀하셨습니다. 처음에는 리더의 마음은 무엇일까 고민을 했지만, 인실리코젠의 필수도서를 읽고 난 후 이해가 되었습니다. 세 번째는 보안인데, 군
복무를 공군 정보 특기로 하였기 때문에 보안에 대해 교육 받으면서 다시 한 번 중요성을 느낄 수 있었습니다. 2주차부터는 파이썬과 리눅스에 관해 기초부터 탄탄하게 알려주셨습니다.
학교에서 배웠던 내용보다 심화한 실무적인 내용으로 구성되어 있어 매우
만족스러웠습니다. 그리고 모든 직원분들이 친절하시고 소통도 잘되었고, 회사 문화까지 체험할 기회를 주셔서 감사하였습니다. 4주 동안 정말 시간이
아깝지 않을 정도로 좋았고 2016년 7월을 잊지 못할 것 같습니다.
마지막으로, (주)인실리코젠 최남우 대표님, 항상
웃으면서 대해주시고 또 바쁜 회사생활 속에서 약간의 자유를 느끼게 해주신 정은미 이사님을 비롯한 모든 분들께 감사의 말씀 전하고
싶고 人CoINTERNSHIP 이란 프로그램을 많은 취업 준비생들에게 추천해주고 싶습니다. "다시 한 번 인실리코젠에 감사드립니다."
경북대학교 신은경

2016년도 하반기 人CoINTERNSHIP에 참여한
신은경입니다. 제가 인턴십을 참여하게 된 계기는 Python, Linux, CLC Genomics Workbench, Main
Workbench, 실제 생물 정보학에서 사용하고 있는 프로그램들에 대하여 배우고자 했던 이유와 앞으로 사회로 나갈 때 필요한
사회생활을 직접 경험하고 싶어 지원하였습니다.
(주)인실리코젠에서 한 달간 회사생활 하면서 다양한
업무들을 보고 경험해 보면서 모르는 문제에 대해서는 항상 눈높이를 맞춰 교육을 진행해 주시고, 알아듣기 쉽게 교육을 진행해 주셔서
처음 하는 프로그램들에 대하여 크게 거부감 없이 배울 수 있었습니다. 한 달 동안 회사에서 느낀 점은 직원분들 모두 맡은 일에
대하여 확신이 있고 일하는데 즐거움을 가진 모습을 볼 수 있었습니다. 이런 모습들을 보면서 저도 제가 비전을 가지고 즐겁게 일을 할
수 있는 생물정보학에서 분석 전문가가 되기 위해 노력을 해야 되겠다는 다짐을 다시 한 번 할 수 있었습니다. 인턴십을 하면서
저에 대하여 다시 생각해보고, 한 달이라는 짧은 시간 동안 같이 지냈던 인턴 동기들과 멘토 이제홍 주임님, 교육들을 담당하셨던
많은 선배님에게서 한 분도 빠짐없이 본받아야 할 점들을 많이 배우고 가는 것 같습니다. 한 달이 짧게 지나간 거 같아 무척
아쉽지만 제가 여기서 배우고자 했던 것들을 다 얻어 가는 것 같아 제 인생에서 기억에 남는 한 달이 될 것 같습니다.
폭염보다 뜨거웠던 7월 한 달을 만들어 주셔서 모든 분께 감사드립니다.
상명대학교 조혜리

‘생물정보학’이라는 전공분야를 대학교 3학년 때 처음 접하고, (주)인실리코젠을 교수님께 추천받아 人Co INTERNSHIP에 지원하게 되었습니다. 처음 인턴십 프로그램을 시작할 때는 새로운 사람들과 낯선 공간에서 일하게 되어 설레기도 하고 긴장하기도 했습니다. 4주가 지난 지금은 제 자신도 적응되었는지 처음에 가졌던 긴장감보다는 익숙함. 그리고 편안함이 더 자리 잡은 것 같습니다. 그래서 그런지 인턴십 프로그램이 끝난다고 생각하니 아쉬운 마음이 큽니다.
인턴십 과정 중 리눅스&파이썬 교육, CLC Genomics Workbench 교육 등 진행되었던 다양한 교육 프로그램이 모두 알차고 재밌었습니다. 그중 가장 제 기억에 남는 것은 자기소개 포트폴리오 발표가 아닐까 싶습니다. 발표준비를 하면서 자연스럽게 실무 능력이 향상되었고, 많은 사람에게 저를 표현할 수 있는, 더 많이 소통할 수 있는 계기가 된 것 같습니다.
매일 아침 일어나 출근을 하면서 피곤하기도 했지만, 퇴근하기 전 작성한 OJT를 보면서 저 스스로 뿌듯함을 느끼고 대견하기도 했습니다. 무엇인가를 완벽하게 익히기에 한 달이라는 기간은 짧은 시간이었지만 처음으로 해본 사회생활이라 많은 것을 느끼고 배울 수 있었습니다. 사회생활의 첫 발걸음을 좋은 곳에서 좋은 분들과 함께하였기에 더욱 의미가 큽니다. 아직은 제 경험이 부족하여, 회사라는 공간이 익숙하지 않던 저에게 따뜻한 시선으로 아낌없는 조언을 해주셨던 대표님을 비롯한 모든 직원분들께 감사드립니다.

Posted by 人Co
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/222
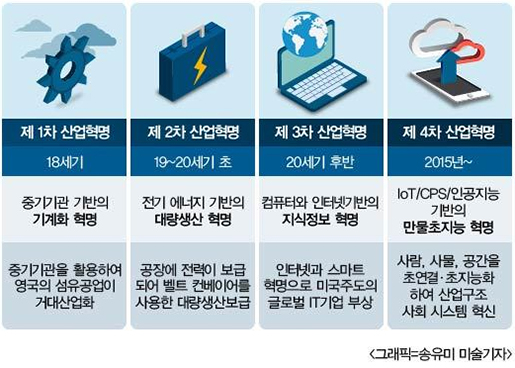
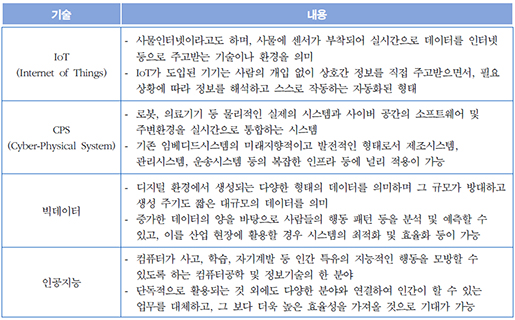 <출처 : 해외 ICT R&D 정책 동향, 정보통신기술진흥센터(2016)>
<출처 : 해외 ICT R&D 정책 동향, 정보통신기술진흥센터(2016)>