
정보보안은 개발단계에서부터! 시큐어코딩(Secure Coding)
- Posted at 2021/05/28 16:33
- Filed under 지식관리

최근 미국의 전기차 기업 테슬라에서 사내 CCTV가 해킹당해 회사 내부의 모습이 노출되는 사건이 있었습니다. 또 송유관 운영회사 콜로니얼 파이프라인이 랜섬웨어 공격을 받아 시스템이 마비되어 수많은 자동차가 연료를 공급받지 못해 대혼란에 빠지는 사태가 발생하기도 했습니다. 두 사건 모두 해킹으로 벌어진 일입니다.

[그림 1] CCTV 해킹으로 인해 노출된 테슬라 회사 내부

해킹 사고는 주로 소프트웨어(SW) 보안취약점을 공격 경로로 이용합니다. 소프트웨어 보안취약점이란 소프트웨어 개발 시 결함이 될 수 있는 논리적인 오류나 버그, 실수 등 이후 취약점으로 발생할 수 있는 근본 원인을 말합니다. 시스템에 보안취약점이 존재하고 그로 인해 정보가 노출된다면 해커는 해당 정보를 이용해 시스템을 공격하는 것입니다. 그럼 개발자는 어떻게 해커들의 공격을 방지할 수 있을까요? 이를 위해 '시큐어코딩(Secure Cording)'이 필요합니다.
시큐어코딩이란 무엇인가요?
시큐어 코딩은 해킹 등 사이버 공격의 원인인 보안취약점을 제거해 안전한 소프트웨어를 개발하는 SW 개발 기법을 말합니다. 개발자의 실수나 논리적 오류로 인해 발생할 수 있는 문제점을 사전에 차단하여 대응하고자 하는 것입니다. 정보보호가 SW 개발의 중요한 주제로 떠오르는 지금 시큐어 코딩은 선택이 아닌 필수가 되었습니다.
시큐어 코딩 가이드
시큐어 코딩은 개발단계에서 적용되기 때문에 개발자의 코딩 작업이 핵심 대상이 됩니다. 그러나 개발자로서 취약점을 모두 고려하는 프로그래밍이란 어려운 일입니다. 따라서 어떠한 규칙에 따라 코딩을 하면 되는지에 대한 기준이 있으면 좋을 것입니다. 그리고 실제로 국내에서는 2012년 12월부터 행정안전부에 의해 시큐어 코딩에 대한 법규가 제정, 시행되어 그 기준을 제시하고 있습니다.

[그림 3] 행정기관 및 공공기관 정보시스템 구축·운영 지침
(출처:행정안전부고시 제2021-3호, 2021.1.19.)
그리고 그 기준은 다음과 같이 50개의 소프트웨어 보안 약점 항목으로 구성되어 있습니다.
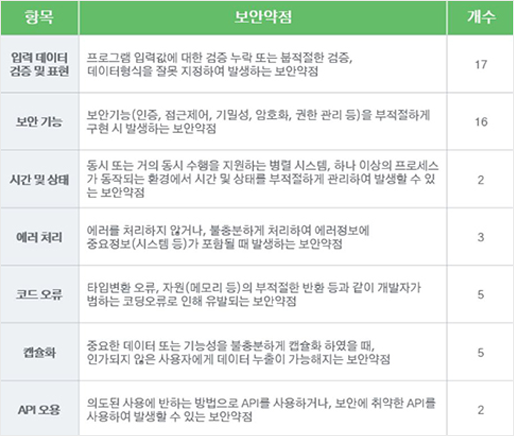
[그림 4] 소프트웨어 개발 보안 가이드
(행정안전부고시 제2021-3호, 2021.1.19.)
이번 블로그 시간에는 소프트웨어 개발 보안 가이드를 기반으로 시큐어코딩의 7가지 유형에 대해 살펴볼 것입니다. 개발 경력이 없으신 분들도 이해할 수 있도록 최대한 쉽게 설명하겠습니다. ")
1. 입력데이터 검증 및 표현
입력데이터 검증 및 표현이란 폼 양식의 입력란에 입력되는 데이터로 인해 발생하는 문제를 예방하기 위해 점검하는 보안 항목을 의미합니다. 쉽게 말해서 사용자가 비정상적인 데이터를 입력하여 시스템에 손상을 주거나 정보를 수정 및 탈취하지 못하도록 방지하는 것입니다. 이는 주로 SQL 인젝션(SQL Injection) 공격을 막기 위한 코딩이라고 할 수 있습니다. SQL(Structured Query Language)은 DB 관리에서 가장 중요한 핵심 요소로 실제로 저장된 데이터를 수정, 삭제, 삽입할 수 있는 기능이 있습니다. 예를 들어 은행 업무 시스템에서는 SQL을 이용해 계좌의 잔액을 조절한다고 볼 수 있는 것입니다. 이토록 중요한 SQL이 악의적인 해커 마음대로 실행될 수 있다면... 정말 치명적인 문제가 될 것입니다. 이를 방어하기 위해 사용자가 입력한 데이터를 확인해 공격 시도로 의심되는 단어를 치환하거나 차단하는 방식을 이용합니다. 이것이 바로 입력데이터 검증 및 표현의 가장 핵심요소라고 말할 수 있겠습니다.
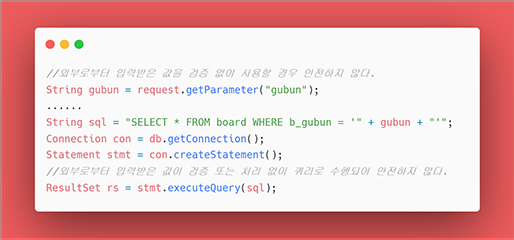
[그림 5] 안전하지 않은 코드의 예 JDBC API
안전하지 않은 코드의 예로, 외부에서 받는 데이터인 'gubun'의 값을 검증 없이 사용하고 있습니다. 이 경우 gubun의 값으로 a' or 1=1 이 들어간다면 board 테이블의 전체 데이터가 조회됩니다.

[그림 6] 안전한 코드의 예 JDBC API
안전한 코드의 예로, 파라미터를 받는 PreparedStatement 객체를 상수 스트링으로 생성하고 파라미터 부분을 setString 등의 메소드로 설정해야 합니다.
2. 보안 기능
보안 기능이란 소프트웨어 개발 구현단계에서 코딩하는 기능인 인증, 접근제어, 기밀성, 암호화 등을 올바르게 구현하기 위한 보안 항목을 의미합니다. 주로 암호와 같이 중요한 정보를 암호화 없이 저장하거나 프로그램 내부에 하드 코딩되어 노출의 위험성이 있는 경우, 인증과 권한 관리를 부적절하게 구현할 시 발생하는 문제가 있습니다. 서두에 말씀드린 테슬라 해킹 사건이 이 항목에 해당합니다. 해커가 이중인증시스템의 취약점을 파악하고 이를 이용해 보안 체계를 우회한 것입니다. 보안 기능은 비인가 접근을 방어하고 저장된 정보를 암호화하여 취약한 기능이 존재하지 않도록 하는 것이 중요하다고 말씀드릴 수 있겠습니다.
3. 시간 및 상태
시간 및 상태는 동시 또는 거의 동시 수행을 지원하는 병렬 시스템이나 하나 이상의 프로세스가 동작하는 환경에서 시간 및 상태를 부적절하게 관리하여 발생할 수 있는 보안 약점입니다. 프로그래밍을 하다 보면 하나의 자원을 다수개의 프로세스가 사용해야 하는 경우가 생깁니다. 이때 자원 공유가 적절히 진행되지 않아 프로그램이 꼬일 수 있게 됩니다. 예를 들어, 프로세스 A는 ①파일이 존재하는지 확인하고 ②파일을 읽는 과정을 진행합니다. 프로세스 B는 파일을 삭제합니다. 만약 프로세스 A의 과정①이 진행되고 과정②가 시작되기 전 프로세스 B가 파일을 삭제해버린다면 프로세스 A가 삭제된 파일 읽기를 시도하므로 *레이스컨디션이 발생합니다. 이 밖에도 종료되지 않는 반복문이나 재귀문을 사용하여 무한루프에 빠지는 것도 시간 및 상태 점검 항목에 포함됩니다.
*레이스컨디션(Race Condition): Race Condition은 두 개 이상의 프로세스가 공용 자원을 병행적으로(concurrently) 읽거나 쓸 때, 공용 데이터에 대한 접근이 어떤 순서에 따라 이루어졌는지에 따라 그 실행 결과가 달라지는 상황을 말한다.
4. 에러 처리
에러 처리는 이름 그대로 에러를 처리하는 방식이 부적절하거나 누락되어 발생하는 보안 항목을 의미합니다. 종종 개발자가 디버깅의 편의성을 위해 에러 메시지를 화면에 출력하는 경우가 있습니다. 에러 메시지는 시스템과 관련된 중요 정보를 포함하는 경우가 많아 공격자의 악성 행위를 도울 수 있습니다. 또한, 오류가 발생할 상황을 적절하게 검사하지 않았거나 잘못된 처리를 한 경우도 에러 처리 항목에 포함됩니다. 에러 처리는 가능한 최소한의 정보만을 담고 있어야 하며, 광범위한 예외 처리보다는 구체적인 예외 처리를 통해 보안 공격을 사전에 방어하는 것이 중요합니다.
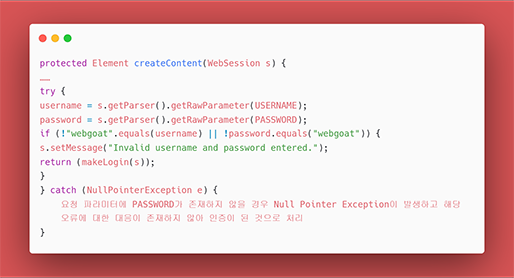
[그림 7] 안전하지 않은 코드의 예 에러처리
안전하지 않은 코드의 예로, try 구문에서 예상되는 예외 상황을 catch 하지만, 그 오류에 대해 추가로 아무 조치를 하지 않고 있습니다. 이런 상황이라면 사용자는 프로그램 내부에서 어떤 일이 일어났는지 전혀 알 수 없게 됩니다.
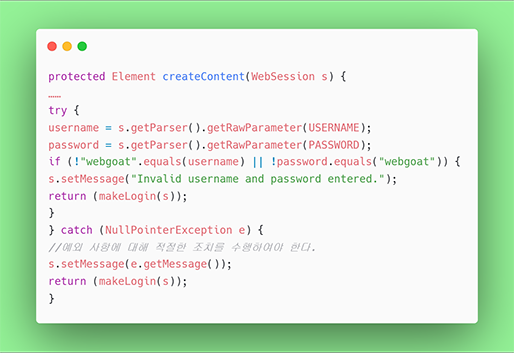
[그림 8] 안전하지 않은 코드의 예 에러처리
예외 catch 후 적절한 조치를 수행한 예
5. 코드 오류
코드 오류는 구현 단계에서 개발자의 실수나 지식 미달로 인한 오류를 예방하기 위한 점검 항목입니다. 주로 형(Type)변환 오류, 자원 반환, NullPointer 참조가 이에 해당합니다. 이 부분은 개발 경험이 없는 경우 이해하기가 조금 어려우실 수 있습니다. Null 값을 체크하지 않고 변수를 사용한다든가 실수로 스레드와 같은 자원을 무한하게 할당하여 시스템에 부하를 주는 경우가 있습니다. 개발자가 잘못된 코딩 습관을 들인다면 코드 오류 항목에서 번번이 보안 취약점에 걸리게 됩니다. 본인만의 보안 코딩 규칙을 만들어서 습관을 들이는 것을 추천합니다.
6. 캡슐화
캡슐화란 객체 지향 방법론에 중요한 개념으로 객체와 필드의 은닉을 통해 외부의 잘못된 사용을 방지하는 것을 의미합니다. 그런데 가끔 시스템의 데이터나 기능을 불충분하게 캡슐화하거나 잘못된 방법을 이용함으로써 보안 취약점으로 작용하는 경우가 있습니다. 부적절한 캡슐화는 정보은닉의 기능을 잃어버립니다. 시스템의 중요 정보가 노출되어 공격자는 이 정보를 이용해 식별 과정을 우회할 수 있습니다. 변수 제어 함수가 노출된다면 공격자는 원하는 값으로 데이터를 외부에서 수정할 수 있게 됩니다.
7. API 오용
API(Application Programming Interface)란 응용프로그램에서 사용할 수 있도록 운영체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스를 뜻합니다. 이렇게만 설명하면 명확한 개념이 잘 떠오르지 않습니다. 쉽게 말씀드리면 API는 프로그램들이 서로 소통하는 것을 도와주는 매개체 역할을 합니다. 음식점에서 주문을 받고 서빙을 해주는 웨이터에 비유할 수 있죠. 이렇듯 개발자는 편리하게 개발하고 유용한 정보를 얻기 위해 API를 활용합니다. 그러나 의도된 사용에 반하는 방법으로 API를 이용하거나, 보안에 취약한 API를 이용한다면 심각한 보안 취약점이 될 수 있습니다. 예를 들어, 만약 공격자에 의해 로컬 DNS 캐시가 오염된 상황에서 DNS만 확인한다면 공격자의 네트워크로 경유하거나 공격자의 서버를 도착지로 인식할 수도 있습니다. 이를 방지하기 위해 보안에 취약한 API 사용은 피해야 하며 DNS가 아닌 IP를 확인하는 것이 중요합니다.
마치며

지금까지 소프트웨어 개발 보안 가이드 시큐어 코딩 7가지 유형에 대해 알아보았습니다. 실제로 개발 보안 가이드를 보시면 더욱 자세한 내용을 확인하실 수 있습니다. 개발 단계뿐만 아니라 분석, 설계 단계의 보안 기법도 자세히 설명되어 있기에 꼭 한번 읽어보시는 것을 추천해 드립니다.
앞으로 디지털 트랜스포메이션과 IoT를 비롯한 SW 시장은 더욱 확대될 것입니다. 하지만 우리가 구성한 네트워크가 보안 위협의 통로가 될 수 있다는 것을 잊지 말아야 합니다. 이제 민관기관에서도 시큐어 코딩을 적극적으로 채택하고 있다고 하니, 시큐어 코딩에 대한 전문성을 길러보시는 것은 어떨까요? :) 오늘 내용이 여러분에게 많은 도움이 되셨길 바랍니다.
앞으로 디지털 트랜스포메이션과 IoT를 비롯한 SW 시장은 더욱 확대될 것입니다. 하지만 우리가 구성한 네트워크가 보안 위협의 통로가 될 수 있다는 것을 잊지 말아야 합니다. 이제 민관기관에서도 시큐어 코딩을 적극적으로 채택하고 있다고 하니, 시큐어 코딩에 대한 전문성을 길러보시는 것은 어떨까요? :) 오늘 내용이 여러분에게 많은 도움이 되셨길 바랍니다.
Posted by 人Co
- Tag
- 보안, 보안 가이드, 소프트웨어, 소프트웨어개발, 시큐어 코딩, 시큐어코딩, 웹보안, 인실리코젠
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/383








 입사지원서_성명_지원부문_20210500.docx
입사지원서_성명_지원부문_20210500.docx
