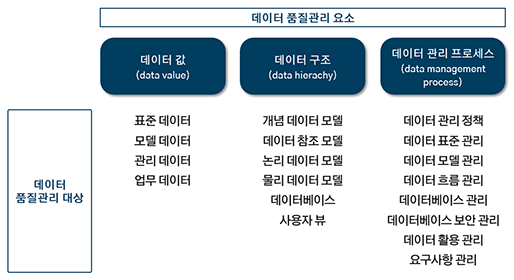
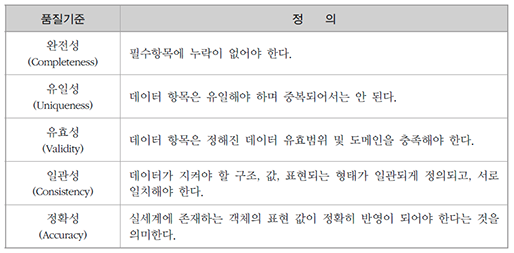
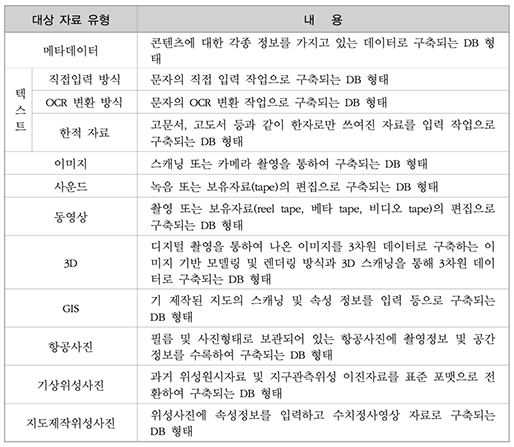
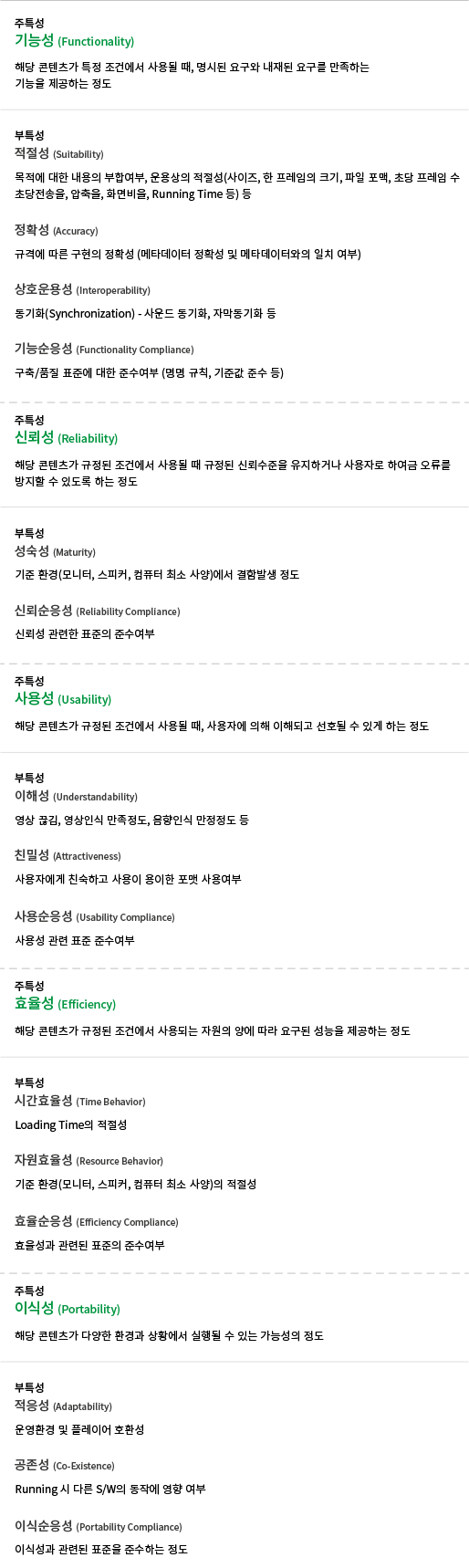
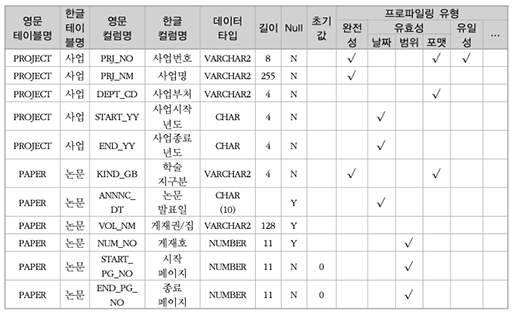
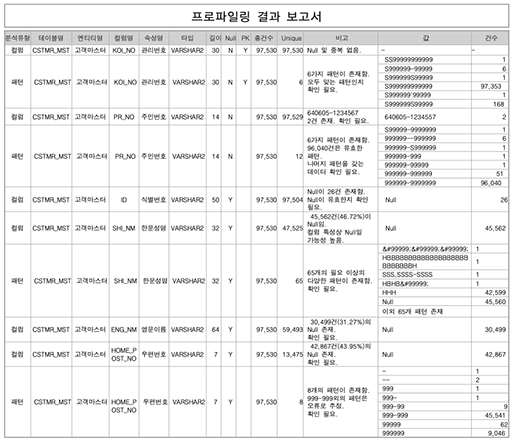
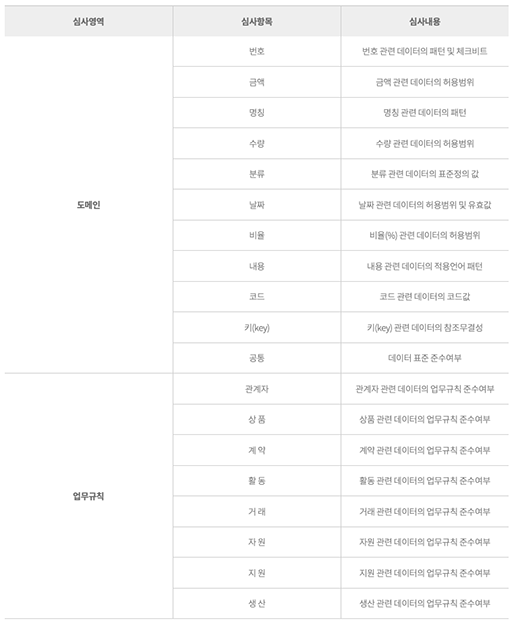
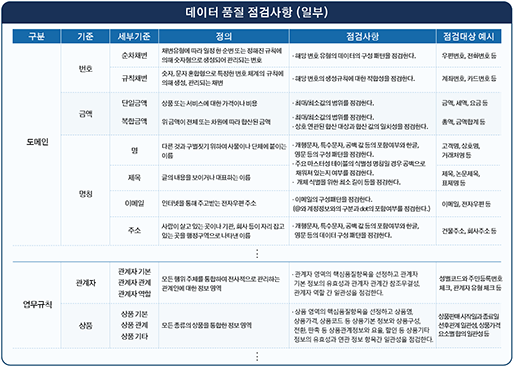
COVID-19 백신에 대하여
- Posted at 2020/12/19 23:34
- Filed under 지식관리

2020년은 코로나의 해라고 말해도 과언이 아닌데요. 코로나19 신규 확진자 추이 그래프만 봐도 아직도 무서운 속도로 증가하는 추세를 볼 수 있습니다.
모두가 코로나 사태가 끝나길 바라는 간절한 마음으로 궁금해하는 것들이 있죠.
언제 이 길고 긴 싸움이 끝이 날까요? 백신 개발은 언제 완료되는 것일까요?
또, 백신 개발은 왜 어려운 걸까요? 그럼 지금부터 하나씩 짚어보도록 하겠습니다.

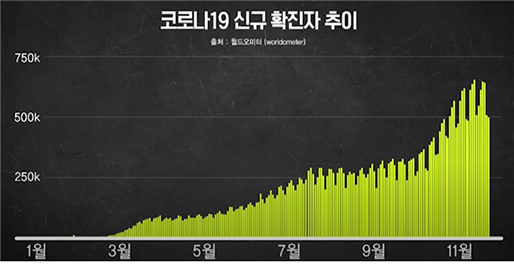
[Fig.1] 코로나19 신규 확진자 추이
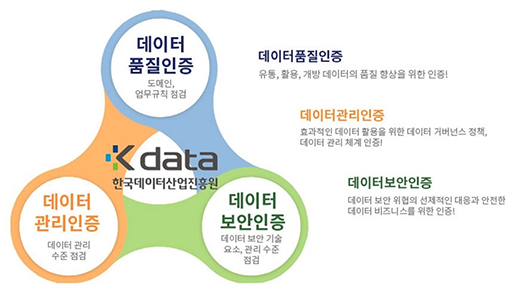
사람에게 질병을 일으키는 수많은 바이러스 중 인류가 박멸한 바이러스는 천연두가 유일하다고 합니다. 이렇게 다양하고 복잡한 바이러스들로부터 우리의 몸을 보호하기 위해 예방접종을 하는데요. 요즘은 예방접종 보다 백신이라는 단어가 더 익숙할 것입니다. 백신을 맞아야 한다는 것은 알고 있지만, 백신이 어떻게 바이러스로부터 우리를 지켜주는지, 또는 다양한 회사들에서 현재 개발되고 있는 백신들이 어떻게 다른지는 관심 있게 찾아보지 않으면 알기 쉽지 않은 내용입니다.
백신! 실제 감염이 됐을 때 재빠르고 강하게 우리 몸의 면역반응을 유도하여 질병을 방어 할 수 있도록 예방의 목적으로 맞는 것입니다. 즉, 백신의 원리는 경험과 기억이라고 말할 수 있습니다. 백신을 맞으면 우리 몸의 면역체계가 활성화 되면서 해당 바이러스에 대해 모의 경험을 하게 되고, 이 경험을 기억하였다가 실제 감염됐을 때 본격적인 면역활성화를 유도하여 질병에 저항할 수 있게 합니다.

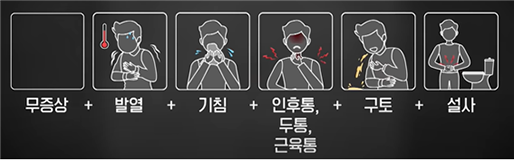
[Fig.2] 코로나19 증상 순서

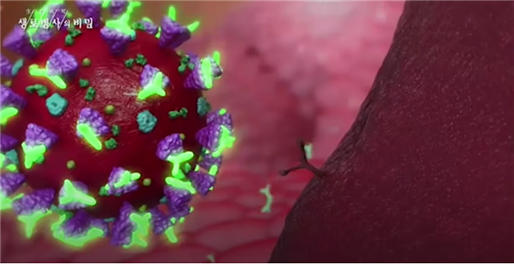
[Fig.3] 스파이크 단백질과 중화항체
(https://www.youtube.com/watch?v=RtIijJd-JC8)
(https://www.youtube.com/watch?v=RtIijJd-JC8)
코로나바이러스에는 세포의 문을 여는 열쇠와 같은 스파이크 단백질(Spike protein)이 존재합니다. 스파이크 단백질은 살아있는 세포 표면의 수용체와 결합하여 세포에 침투하게 되고 우리 몸의 시스템을 이용하여 바이러스 자신을 복제하게 됩니다. 즉, 이 스파이크 단백질이 수용체 단백질과 결합하게 되면 바이러스는 체내로 들어오게 됩니다. 따라서 이 스파이크 단백질을 없애는 것이 감염을 피하는 중요한 요소이고, 백신 개발도 이 부분에 집중하고 있습니다. 즉, 수용체 대신 스파이크 단백과 결합하여 중화시키는 체내 중화항체를 유도하는 백신이 개발되고 있습니다. 그림에서 보시는 것과 같이 바이러스 표면의 보라색 뾰족한 것이 스파이크 단백질이고, 형광으로 표시된 것이 중화항체입니다.



- 스파이크 단백질: 바이러스 외피에서 바깥으로 돌출된 단백질
[Fig.4] 코로나19 백신 종류
현재 코로나바이러스가 예상치 못하게 전 세계적으로 확산세가 지속하면서 화이자, 모더나, 아스트라제네카 등 다양한 제약회사에서 백신을 개발 중입니다.


- 바이러스 벡터 백신(virus-vector vaccines) 바이러스 항원 유전자를 다른 안전한 바이러스에 넣어 투여하는 방식으로, 인체에 해를 끼치지 않는 바이러스를 운반체(벡터)로 이용하는 백신
- 사백신 또는 불활성화 백신 (Inactivated vaccine) 병원체를 열 또는 포르말린 등으로 처리해 활성을 없앤 후 병원체 전체 또는 일부를 추출하여 항원으로 사용하는 방식으로, 바이러스 독성을 없애기 때문에 안전하지만, 스파이크 단백질이 변형될 수 있는 단점을 가진 백신
- DNA 백신 바이러스 항원을 발현할 수 있는 DNA를 투여하는 방법으로, 미리 개발해둔 범용 백신 플랫폼에 바이러스의 특정 유전자를 집어넣어 사용하는 백신
- RNA 백신 바이러스 항원 유전자를 RNA 형태로 투여하는 방식을 가진 백신
- 재조합 단백질 백신 (protein-based vaccines) 바이러스의 특정 단백질 조각을 항원으로 사용하는 백신으로, 대장균이나 효모에서 유전자 재조합 기술로 인공적인 항원 단백질을 만들어 투여하는 백신. 상대적으로 안전하지만, 면역 활성화 효과가 떨어질 수 있음. B형 간염 백신이 대표적
- 바이러스 유사 입자 백신 (virus-like particles; VLP) 바이러스 항원 단백질을 실제 바이러스와 유사한 입자 모양으로 만든 가짜 바이러스를 만들어서 사용하는 백신. 자궁경부암 백신이 대표적
[Fig.5] 코로나19 백신 개발 기간 비교
RNA, DNA 백신과 같은 기술 덕분에 평균 5-10년 정도 소요되던 백신의 개발 기간이 1년으로 단축되었다고 합니다. 하지만 아직 상용화된 전례가 없어서 대량 생산이나 유통 면에서 현실적인 장벽이 많다고 합니다. 개발 기간이 이렇게 짧을 수 있었던 이유는, 전통적인 백신인 불활성화 백신이나 단백질 기반 백신들은 단백질을 생산하는 생물 공정 배양기가 필요하여 생성이 어려웠기 때문입니다. 하지만 RNA나 DNA는 인공적으로 실험실 내에서 쉽게 증폭할 수 있으므로 큰 배양기 없이 빠른 생산이 가능합니다. 하지만 -70℃에서 -20℃ 정도의 굉장히 낮은 온도에서 보관하고 유통되어야 한다는 단점이 있습니다. 제약업체에서 콜드체인을 통해 유통을 진행하는 이유가 이 때문입니다.

여기서 mRNA 백신에 대하여 조금 더 알아보도록 하겠습니다. mRNA는 세포가 살아가는 데 중요한 역할을 담당하는 유전물질인 리보핵산(RNA) 중 하나입니다. mRNA는 DNA 안에 저장된 인체 유전자 정보가 단백질이란 형태로 발현되는 과정에서 정보를 전달하는 역할을 합니다. mRNA 백신을 만들기 위해서는 바이러스의 유전물질 중에서 감염에 큰 역할을 하는 항원 생산을 담당하는 유전자가 무엇인지를 먼저 파악해야 합니다. 그래야만 적절한 항체 형성을 유도하여 감염을 예방할 수 있기 때문입니다. 백신 제조사는 이와 같은 주요 유전자로부터 mRNA를 만들고 백신에 활용하는 것입니다. 일반적으로 바이러스의 단백질, 즉 외부 항원이 인체에 들어오게 되면 몸에서는 면역반응이 일어나 결과적으로 바이러스에 대항하는 항체가 형성됩니다. mRNA 백신은 기존 사백신이나 생백신처럼 바이러스 단백질 대신에, 말 그대로 mRNA 성분을 주사합니다. mRNA 백신을 주사하게 되면 체내에서는 바이러스 단백질 항원이 만들어지고, 해당 단백질에 대해 인체 면역체계가 항체를 형성할 수 있도록 유도하는 과정을 거치게 되는 것입니다. 기존 백신들이 단백질 원료 성분을 배양하는 등의 긴 절차를 거쳐야 했던 반면, mRNA 백신 기술을 활용하면 단백질 성분을 배양하는 과정이 생략되게 되는 겁니다. 무엇보다 전문가들은 기존 백신과 달리 생산과정이 빠르고, 저렴하게 생산할 수 있다는 점에서 mRNA 백신을 높이 평가합니다. 과거 백신 개발에만 10~15년 정도가 걸렸다는 점을 고려해보면, 빠른 생산이 가능한 mRNA 백신 기술의 발전은 환자 관리가 급박한 코로나19 팬데믹 상황에서 큰 힘을 보여줄 것으로 기대됩니다.

현재 화이자와 모더나가 개발한 mRNA 백신 후보는 코로나19 바이러스의 스파이크 단백질을 만드는 mRNA를 바탕으로 개발됐습니다. mRNA만 주입하게 되면 체내에 들어가서 금방 파괴될 수 있으므로, 세포 내에서 필요로 하는 단백질이 만들어질 때까지 유효성분이 파괴되지 않도록 포장하는 전략이 필요합니다. 두 회사 모두 mRNA에 당 성분을 결합시키고, 세포막과 같은 지질 성분으로 이를 감싸 나노 크기 수준의 지질 입자 형태로 체내에 주입하는 것은 공통적입니다. 아직 구체적인 논문이 발표되지 않아 상세한 비교는 어렵겠지만, 전문가들은 화이자와 모더나의 백신은 일단 mRNA 변형 방법, 나노 입자 크기를 만드는 지질 성분 구조, 혹은 1회 주사하는 mRNA 양에 차이가 있을 것으로 보고 있습니다.

모더나가 개발 중인 백신 후보 'mRNA-1273'을 보면, -20℃에서는 최대 6개월, 2~8℃에 해당하는 냉장상태에서는 최대 30일, 냉장고에서 꺼낸 뒤에도 실온 상태에서 최대 12시간 동안 안정적으로 유지된다고 합니다. 이에 비해 화이자와 독일 바이오기업인 바이온엔테크(BioNTech)가 개발한 백신 후보인 'BNT 162b2'는 -70℃에서 유통과 보관이 이루어져야 합니다. 모더나의 백신이 강조한 영하 20도에서의 유통 보관방법은 표준 냉동고 온도를 사용하는 방식인데, 이는 급속 냉동보다 훨씬 접근성이 쉬운 유통 보관 방식입니다. 전 세계 대부분의 제약 유통회사들이 -20℃에서 제품을 보관하고 유통 배송할 수 있기 때문입니다. 화이자 백신 후보는 1회 주사에 mRNA를 30μg, 모더나 백신은 100μg 주입하게 되는데, 이러한 주입되는 mRNA 양의 차이나 나노입자 구조 차이 등으로 인해 유통 보관 온도에 차이가 나타난다고 합니다.

왜 이제서야 mRNA 백신이 나오는지 궁금해하실 수도 있습니다. 1990년대부터 과학자들은 생쥐 실험을 통해 세포에 RNA를 주입하면 면역반응을 유도할 수 있는 단백질이 생산된다는 것을 알아냈습니다. 이론적으로는 감염병을 일으키는 바이러스의 유전정보만 알면 바로 그에 맞는 mRNA를 합성해 인체에서 면역반응을 유도할 수 있습니다. 그런데 RNA 백신은 몸 안에서 단백질을 많이 만들어내지 못하고, 잘못하면 단백질을 만들기 전에 쉽게 분해된다는 단점이 있습니다. 이런 문제는 최근에서야 RNA 합성과 변형 기술이 발전하면서 많이 해결됐습니다. 특히 지방 나노 입자로 mRNA를 감싸는 기술이 개발된 덕분에 mRNA가 체내에서 오래 유지될 수 있게 된 점도 mRNA 백신의 탄생을 이끈 주요 요인입니다. 그런데도 mRNA는 여전히 불안정한 물질이어서, 이번 화이자 백신 같은 경우에는 -70℃에서 보관해야 합니다. 화이자와 모더나가 다른 제약회사에 비해 빠르게 코로나19 백신을 개발할 수 있었던 데는, 기존에 암이나 광견병 등의 백신을 mRNA로 개발해서 임상을 진행한 경험이 있는 회사들이기 때문이라고 합니다.

3상 임상에서 90% 이상의 효과를 얻었다 해도 항체 유지 기간이 너무 짧으면 백신의 효능이 상당히 떨어질 수밖에 없다는 점과 코로나19 바이러스 감염에 특히 취약한 노약자 등에서도 같은 효과를 기대할 수 있는지 절대적인 데이터가 아직 부족하다는 평가가 있습니다. 백신 접종 인원에서의 중증 부작용 발생 위험 등도 추가로 검증해봐야 할 문제로 남겨졌습니다.

- 콜드체인: 냉동이나 냉장을 통해서 유통하는 방식
여기서 mRNA 백신에 대하여 조금 더 알아보도록 하겠습니다. mRNA는 세포가 살아가는 데 중요한 역할을 담당하는 유전물질인 리보핵산(RNA) 중 하나입니다. mRNA는 DNA 안에 저장된 인체 유전자 정보가 단백질이란 형태로 발현되는 과정에서 정보를 전달하는 역할을 합니다. mRNA 백신을 만들기 위해서는 바이러스의 유전물질 중에서 감염에 큰 역할을 하는 항원 생산을 담당하는 유전자가 무엇인지를 먼저 파악해야 합니다. 그래야만 적절한 항체 형성을 유도하여 감염을 예방할 수 있기 때문입니다. 백신 제조사는 이와 같은 주요 유전자로부터 mRNA를 만들고 백신에 활용하는 것입니다. 일반적으로 바이러스의 단백질, 즉 외부 항원이 인체에 들어오게 되면 몸에서는 면역반응이 일어나 결과적으로 바이러스에 대항하는 항체가 형성됩니다. mRNA 백신은 기존 사백신이나 생백신처럼 바이러스 단백질 대신에, 말 그대로 mRNA 성분을 주사합니다. mRNA 백신을 주사하게 되면 체내에서는 바이러스 단백질 항원이 만들어지고, 해당 단백질에 대해 인체 면역체계가 항체를 형성할 수 있도록 유도하는 과정을 거치게 되는 것입니다. 기존 백신들이 단백질 원료 성분을 배양하는 등의 긴 절차를 거쳐야 했던 반면, mRNA 백신 기술을 활용하면 단백질 성분을 배양하는 과정이 생략되게 되는 겁니다. 무엇보다 전문가들은 기존 백신과 달리 생산과정이 빠르고, 저렴하게 생산할 수 있다는 점에서 mRNA 백신을 높이 평가합니다. 과거 백신 개발에만 10~15년 정도가 걸렸다는 점을 고려해보면, 빠른 생산이 가능한 mRNA 백신 기술의 발전은 환자 관리가 급박한 코로나19 팬데믹 상황에서 큰 힘을 보여줄 것으로 기대됩니다.
현재 화이자와 모더나가 개발한 mRNA 백신 후보는 코로나19 바이러스의 스파이크 단백질을 만드는 mRNA를 바탕으로 개발됐습니다. mRNA만 주입하게 되면 체내에 들어가서 금방 파괴될 수 있으므로, 세포 내에서 필요로 하는 단백질이 만들어질 때까지 유효성분이 파괴되지 않도록 포장하는 전략이 필요합니다. 두 회사 모두 mRNA에 당 성분을 결합시키고, 세포막과 같은 지질 성분으로 이를 감싸 나노 크기 수준의 지질 입자 형태로 체내에 주입하는 것은 공통적입니다. 아직 구체적인 논문이 발표되지 않아 상세한 비교는 어렵겠지만, 전문가들은 화이자와 모더나의 백신은 일단 mRNA 변형 방법, 나노 입자 크기를 만드는 지질 성분 구조, 혹은 1회 주사하는 mRNA 양에 차이가 있을 것으로 보고 있습니다.
모더나가 개발 중인 백신 후보 'mRNA-1273'을 보면, -20℃에서는 최대 6개월, 2~8℃에 해당하는 냉장상태에서는 최대 30일, 냉장고에서 꺼낸 뒤에도 실온 상태에서 최대 12시간 동안 안정적으로 유지된다고 합니다. 이에 비해 화이자와 독일 바이오기업인 바이온엔테크(BioNTech)가 개발한 백신 후보인 'BNT 162b2'는 -70℃에서 유통과 보관이 이루어져야 합니다. 모더나의 백신이 강조한 영하 20도에서의 유통 보관방법은 표준 냉동고 온도를 사용하는 방식인데, 이는 급속 냉동보다 훨씬 접근성이 쉬운 유통 보관 방식입니다. 전 세계 대부분의 제약 유통회사들이 -20℃에서 제품을 보관하고 유통 배송할 수 있기 때문입니다. 화이자 백신 후보는 1회 주사에 mRNA를 30μg, 모더나 백신은 100μg 주입하게 되는데, 이러한 주입되는 mRNA 양의 차이나 나노입자 구조 차이 등으로 인해 유통 보관 온도에 차이가 나타난다고 합니다.
왜 이제서야 mRNA 백신이 나오는지 궁금해하실 수도 있습니다. 1990년대부터 과학자들은 생쥐 실험을 통해 세포에 RNA를 주입하면 면역반응을 유도할 수 있는 단백질이 생산된다는 것을 알아냈습니다. 이론적으로는 감염병을 일으키는 바이러스의 유전정보만 알면 바로 그에 맞는 mRNA를 합성해 인체에서 면역반응을 유도할 수 있습니다. 그런데 RNA 백신은 몸 안에서 단백질을 많이 만들어내지 못하고, 잘못하면 단백질을 만들기 전에 쉽게 분해된다는 단점이 있습니다. 이런 문제는 최근에서야 RNA 합성과 변형 기술이 발전하면서 많이 해결됐습니다. 특히 지방 나노 입자로 mRNA를 감싸는 기술이 개발된 덕분에 mRNA가 체내에서 오래 유지될 수 있게 된 점도 mRNA 백신의 탄생을 이끈 주요 요인입니다. 그런데도 mRNA는 여전히 불안정한 물질이어서, 이번 화이자 백신 같은 경우에는 -70℃에서 보관해야 합니다. 화이자와 모더나가 다른 제약회사에 비해 빠르게 코로나19 백신을 개발할 수 있었던 데는, 기존에 암이나 광견병 등의 백신을 mRNA로 개발해서 임상을 진행한 경험이 있는 회사들이기 때문이라고 합니다.
3상 임상에서 90% 이상의 효과를 얻었다 해도 항체 유지 기간이 너무 짧으면 백신의 효능이 상당히 떨어질 수밖에 없다는 점과 코로나19 바이러스 감염에 특히 취약한 노약자 등에서도 같은 효과를 기대할 수 있는지 절대적인 데이터가 아직 부족하다는 평가가 있습니다. 백신 접종 인원에서의 중증 부작용 발생 위험 등도 추가로 검증해봐야 할 문제로 남겨졌습니다.
전 세계 제약사들에게 코로나19 백신뿐만 아니라 치료제 개발 또한 중요한 과제로 남아있습니다. 치료제에는 크게 항체치료제와 혈장치료제가 개발되고 있습니다. 항체치료제와 혈장치료제 모두 바이러스 표면 스파이크 단백질을 표적으로 한 항체를 이용한다는 점에서 원리는 같습니다. 항체치료제는 스파이크 단백질을 표적으로 한 단클론항체를 인공적으로 합성해 만드는 반면 혈장치료제는 완치자의 혈장에 존재하는 항체들을 농축해 투여하는 방식이라는 차이가 있습니다. 화학적 치료제에 비해 부작용의 가능성이 작고 예방 용도로도 사용 가능해 개발이 활발하게 진행 중입니다. 치료제 개발에 모든 제약사가 힘쓰는 가운데 AI 또한 치료제 개발에 크게 이바지하고 있다고 합니다. AI는 어떻게 치료제에 도움을 줄 수 있을까요?
구글의 인공지능(AI) 자회사인 딥마인드는 단백질 구조를 파악하는 AI인 알파폴드가 AI들의 단백질 구조 예측 능력을 평가하는 대회인 CASP에서 유전정보만으로 과학자들이 실험으로 사전에 밝혀낸 단백질 구조와 90% 이상 일치하는 결과를 얻었다고 합니다. 조금 더 자세히 살펴보면 과거 실험을 통해 확인된 단백질의 3차원 구조정보와 DNA 유전 정보를 알파폴드에게 학습시켜 수차례 수많은 정보를 반복 학습시키는 딥러닝을 통해 알파폴드는 아미노산 서열 정보와 단백질 입체 구조 간의 연관관계를 스스로 익혀나가는 원리입니다. 이러한 단백질 구조 예측 기술은 특히 신약 개발에 유용하게 사용됩니다. 예를 들어 단백질 구조 예측 기술을 통해 코로나19 바이러스의 스파이크 단백질 구조를 예측해서 스파이크가 인체 세포에 달라붙지 못하게 이 돌기를 감쌀 수 있는 단백질을 디자인하는 식으로 신약을 개발하는 것입니다. 특히 단백질 구조 예측에서 비용과 시간이 크게 절약되면 코로나19를 비롯한 감염병에 신속한 대응이 가능해질 전망이라고 합니다. ㈜인실리코젠 또한 "AI drives Bioinformatics"이라는 슬로건 아래 새롭게 펼쳐질 미래를 준비하고 있습니다. 이렇게 주변의 곳곳에서 AI가 우리들의 삶 깊숙한 곳까지 함께하고 있는데요, 앞으로도 AI의 활용이 기대됩니다.
전 세계적으로 코로나19 라는 팬데믹으로 평범한 일상조차 누리지 못하고 있는 상황이 오랜 시간 동안 계속되고 있습니다. 이러한 상황 속에서 소중한 친구와 가족들을 마음 편히 만나지 못하고 있지만, "위기를 기회로"라는 말이 있듯이 이번 코로나19 사태라는 위기가 RNA 백신 개발 기술을 고도화할 기회가 될 수 있길 바라봅니다. 일상의 소중함을 알아가고 나 자신과 주변을 되돌아보고 살필 수 있는 시간이 되었으면 좋겠으며, 백신에 대한 여러분들의 궁금증에 도움이 되었길 바라며 이 글을 마칩니다.
감사합니다.

- Larsen JR, Martin MR, Martin JD, Kuhn P, Hicks JB. Modeling the Onset of Symptoms of COVID-19. Front Public Healt h. 2020 Aug 13;8:473. doi: 10.3389/fpubh.2020.00473. PMID: 32903584; PMCID: PMC7438535.
- 카이스트 신의철 교수의 알기 쉬운 '면역&바이러스' 이야기
- http://www.medicaltimes.com/Users/News/NewsView.htmlmode=view&ID=1137247&REFERER=NP
- https://www.chosun.com/economy/science/2020/12/06/RO3QWO2FNRD2ZAMNHWTE73SK3Q/
- https://www.youtube.com/watch?v=RtIijJd-JC8
- https://www.youtube.com/watchv=gJ4iTzkahdo&list=PLEFnIniFC1sBoRARnMNn2IluUFULbnU8Y&index=10
- https://www.mk.co.kr/news/it/view/2020/12/1234316/
- http://www.aitimes.com/news/articleView.html?idxno=134544
작성 : RDC 손효정 연구원
Posted by 人Co
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/367