1인 미디어와 동영상
2019년 현재, 1인 미디어 시대를 사는 우리에게 가장 친숙한 정보 매체는 동영상입니다. 유튜브 같은 동영상 플랫폼을 통하여, 동영상 파일을 업로드하거나 다운로드한 경험이 있을 것입니다. 이때 다양한 동영상 파일 형식들이 지원되고 있으며, 이 중 많이 사용되는 형식으로는 MPEG, MPEG2, MPEG4, MP4 등이 있습니다. 언급한 동영상 형식은 모두 MPEG와 동일하거나 발전된 형식이며, MPEG라는 키워드 자체는 생소하지 않으리라고 생각합니다. 이번 시간에는 이 MPEG가 무엇이며, 우리가 알고 있는 유전체와 어떤 관계가 있는지 알아보도록 하겠습니다.
MPEG이란?
MPEG(엠펙)은 1988년에 설립된 표준화 전문 그룹으로 풀네임은 Moving Picture Experts Group(동영상 전문 그룹)입니다. 좁은 의미로는 그 이름을 가진 코덱이나 파일 확장자이기도 하지만 넓은 의미이자 본래 의미로 따지면 코덱이나 확장자만이 아닌 표준 규격 자체를 포괄하는 용어입니다. 이 그룹에는 미국의 AT&T, 영국의 BritishTelecom, 일본의 NTT, 미쓰비시, 후지쯔와 같은 비디오 및 통신장비 업체들이 주로 소속되어 있습니다. 정지된 화상을 압축하는 방법을 고안하고 있는 JPEG과는 달리 MPEG은 시간에 따라 연속적으로 변하는 동화상 비디오, 오디오 데이터의 압축과 해제 방식을 규정하고 있습니다[그림 1].

[그림 1] MPEG 메인 사이트
앞서, MPEG가 동영상의 표준 규격 자체 즉 표준화된 형식이라고 언급하였습니다. 이번 글의 중요한 주제이자 키워드가 될 수 있습니다. 먼저, 표준화의 정의는 여러 가지 제품들의 종류와 규격을 표준에 따라 제한하고 통일하는 것을 말합니다. 이와 비슷한 말로 정규화가 있습니다. 그럼 왜 표준화가 필요한 걸까요? 일반적인 정보 통신 표준의 의의는 기술의 공개 및 시스템 간의 호환성을 통한 신기술 확산 및 공유에 있습니다. 좀 더 자세히 말하면, MPEG의 표준화는 동영상 압축 및 압축 해제 기술의 확산 및 공유에 매우 큰 영향을 주었다고 할 수 있습니다. 현재, MPEG는 대부분의 디지털 미디어 콘텐츠에 적용되고 있으며, 다양한 형태로 다양한 플랫폼에서 확인할 수 있습니다[그림 2, 3].

[그림 2] 디지털 미디어 콘텐츠와 압축
(출처 : MPEG-G document, Workshop on Genomic Information Representation held in San Diego on 18th April 2018)

[그림 3] 압축 전송의 자유도
(출처 : MPEG-G document, Workshop on Genomic Information Representation held in San Diego on 18th April 2018)
유전체 생산 속도 증가와 압축의 필요성
인간의 유전체 지도를 해독하기 위해 13년간 진행된 인간 게놈 프로젝트(Human Genome Project)가 2003년 종료된 이후, 유전체 분석을 위해 필요한 비용은 기하급수적으로 감소하였습니다. 2014년 미국의 유전체 분석 장비 제조업체인 일루미나(Illumina)는 같은 해 1월 개최된 JP모건 헬스케어 컨퍼런스에서 1,000달러(약 110만 원)로 한 사람의 게놈 전체를 해독할 수 있는 게놈 분석 장비 HiSeq X10 출시를 발표하면서 1,000달러 게놈 시대를 이끌었습니다.
그 이후 2018년에 들어, Veritas Genetics는 999달러의 전체 게놈 시퀀싱 서비스 가격을 80% 인하하여 선착순 1,000명에게 199달러에 유전자 분석 서비스(결과 해석 포함)를 제공한 사례가 있습니다. 이는 1,000달러의 1/10 수준인 100달러(약 11만 원)로 한 사람의 유전체 서열 전체를 해독할 수 있는 100달러 게놈 시대가 곧 온다는 것을 예고합니다.
유전체 생산 비용의 감소는 관련 산업의 발전을 이끌고 있으며, 분석된 대용량의 유전체 데이터는 빅데이터 기술과 맞물려 유전체 분석 시장을 빠르게 발전시켰습니다. Google과 Amazon은 보유하고 있는 클라우드 시스템을 활용하여 유전체 빅데이터 클라우드 서비스를 제공하고 있으며, 23andme와 같은 개인 전장유전체 분석서비스 등 다양한 산업화가 이루어졌습니다. 또한, 국외 유전체 아카이브 중 하나인 EMBL-EBI에 따르면, 2018년부터 10 페타바이트(petabyte) 규모의 데이터를 서비스하고 있습니다(그림4). 이제는 페타바이트(petabyte)급의 생산 시대로 들어왔으며, 이는 현존하는 디지털 데이터 중 가장 빠르게 생산하는 유전체 빅데이터가 된 것입니다.
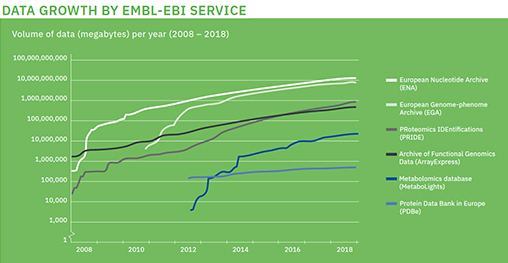
[그림 4] EBI, 데이터 서비스 용량
(출처 : EMBL EBI annual-report-2018)
대용량 유전체 데이터의 급격한 증가는 이를 저장하는 저장 매체의 발전 속도를 추월하였기에, 저장 및 관리하는 비용의 감소 및 전송의 필요성이 지속해서 제기되었고, 이는 MPEG와 같은 압축 표준이 필요한 이유입니다.
유전체 압축 표준화
유전체 압축에 대한 표준화는 2014년부터 이루어지고 있습니다. 2014년 3월 스페인의 발렌시아에서 진행된 108차 MPEG(Moving Picture Experts Group) 회의에서 유전체 데이터의 압축, 저장, 그리고 스트리밍에 대한 필요성이 최초로 제기되었습니다. 처음 시작부터, 비디오 압축 전문가와 생물정보 전문가에 의해 공동으로 작성되었습니다. 전통적으로 오디오와 비디오 데이터의 압축과 처리에 대한 표준화를 진행해온 MPEG에 유전체 데이터에 대한 표준 이슈를 제기한 것은 특이하지만, 디지털 데이터의 종류를 확장하면 MPEG에서 다룰 만한 표준이라고 볼 수도 있습니다. MPEG는 유전체 표준의 필요성을 받아들여, 미래 미디어 서비스로 대두하고 있는 몰입형 미디어(Immersive Media) 표준개발을 위한 MPEG-I 프로젝트를 2017년부터 시작하였습니다. 이 중 유전체 압축 관련된 표준화도 진행하고 있는데 이를 MPEG-G라고 합니다[그림 5].
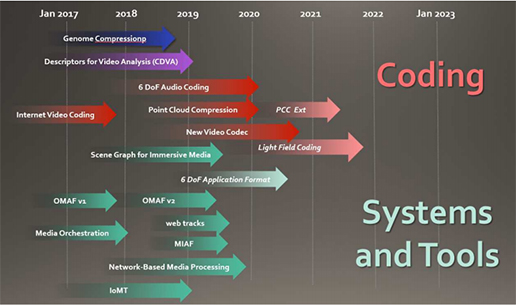
[그림 5] MPEG 표준개발 로드맵
(출처 : 한국정보통신기술협회 TTA연구보서, MPEG뉴디미어 포럼 2019)
MPEG-G
생명 공학 표준 (ISO TC 276 / WG 5)을 위해 MPEG와 ISO 기술위원회가 공동으로 개발한 MPEG-G 표준은 유전체 데이터를 처리(분석, annotation 등) 시 발생하는 문제 해결 및 비용 절감을 위한 최초의 국제 표준입니다. 새로운 압축 및 전송 기술뿐만 아니라 메타 데이터의 형태로 연결하는 표준 규격 정보와 시퀀싱 데이터를 효율적으로 처리할 수 있는 상호 운용 가능한 애플리케이션 및 관계된 서비스업계 전반의 에코시스템을 구축하기 위한 API (Application Programming Interfaces)를 제공합니다.
에코시스템(ecosystem) – 원래 생물학 용어로, 자연환경과 생물이 서로 영향을 주고받으면서 함께 생존해 나가는 자연계의 질서를 말합니다. 이것을 1993년 미국하버드대 연구교수인 제임스 무어(Moore)가 비즈니스에 접목해 비즈니스 에코시스템이란 용어를 만들었습니다. 주로 IT 분야의 여러 기업이 몇몇 리더 기업을 중심으로 경쟁과 협력을 통해 공생(共生)하고 함께 발전해 나가는 모습을 지칭합니다.
MPEG-G 표준의 적용을 통하여, 압축 데이터에 대한 선택적 액세스(access), 데이터 스트리밍(streaming), 압축 파일 연결, 유전체 연구 집계, 시퀀싱 데이터 및 메타 데이터의 선택적 암호화 등 다양한 사례에서 필요한 데이터 압축 및 전송을 지원하게 됩니다. (그림 6.)
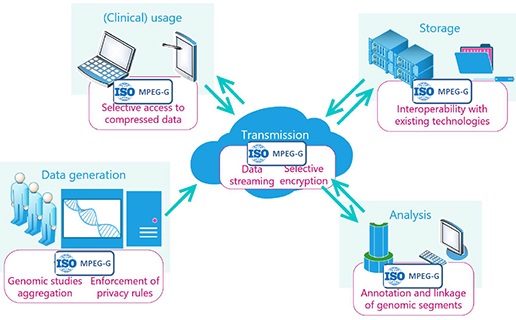
[그림 6] MPEG-G 표준을 활용한 에코시스템의 완벽한 지원
(출처 : : MPEG-G document, Workshop on Genomic Information Representation held in San Diego on 18th April 2018)
특히 고성능 컴퓨터 기술(HPC, High Performance Computing)과 연계하여, 유전체 아카이브의 익명데이터와 의학 및 헬스산업의 데이터를 연결하는 중요한 가교역할을 할 것으로 기대하고 있습니다[그림 7].
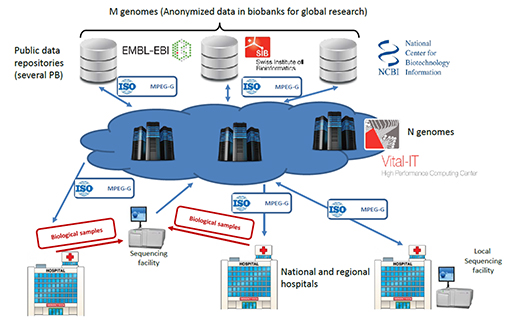
[그림 7] HPC환경의 유전체 분석을 위한 MPEG-G의 역할
(출처 : MPEG-G document, Workshop on Genomic Information Representation held in San Diego on 18th April 2018)
마치면서
정리하면, MPEG-G 표준은 현재 유전체 정보 처리의 효율 및 경제성을 고려한 규격이며, 유전체 압축 기술의 문제점과 한계를 해결하기 위한 가장 규모가 큰 국제 협력이자 노력입니다. 2019년 현재, MPEG-G 표준의 진행은 유전체 파일의 특징 및 규격의 표준에 대한 API 부분은 FDIS(Final Draft International Standard, 최종 규격 전 초안) 단계로 완료되었으나, 실제 적용을 위한 유전체 파일 형식에 따른 압축 방법이나 표준 압축 알고리즘 등 은 아직 연구 논문 수준으로 좀 더 시간이 필요합니다. 유전체 정보를 다루는 견해에서 MPEG-G 표준의 다음 소식을 하루빨리 기다려봅니다.
참고자료
작성 : 대전지사 홍지만 선임
Posted by 人Co


 人CoINTERNSHIP_지원서_2019.doc
人CoINTERNSHIP_지원서_2019.doc