1. 개요¶
Contents
1.1. KinMatch (DNA 유전정보기반 혈연관계 전문 검색 엔진)¶
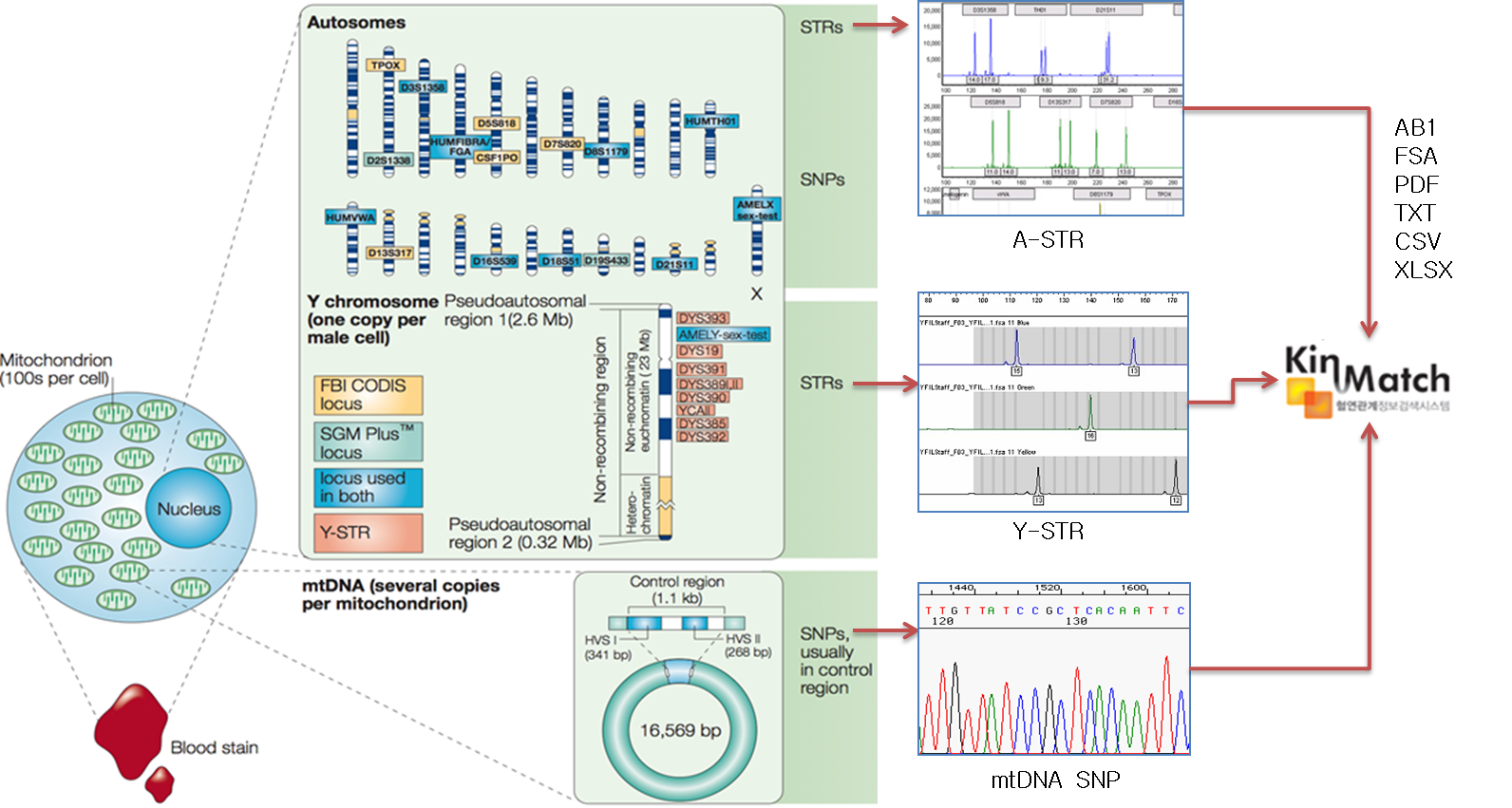
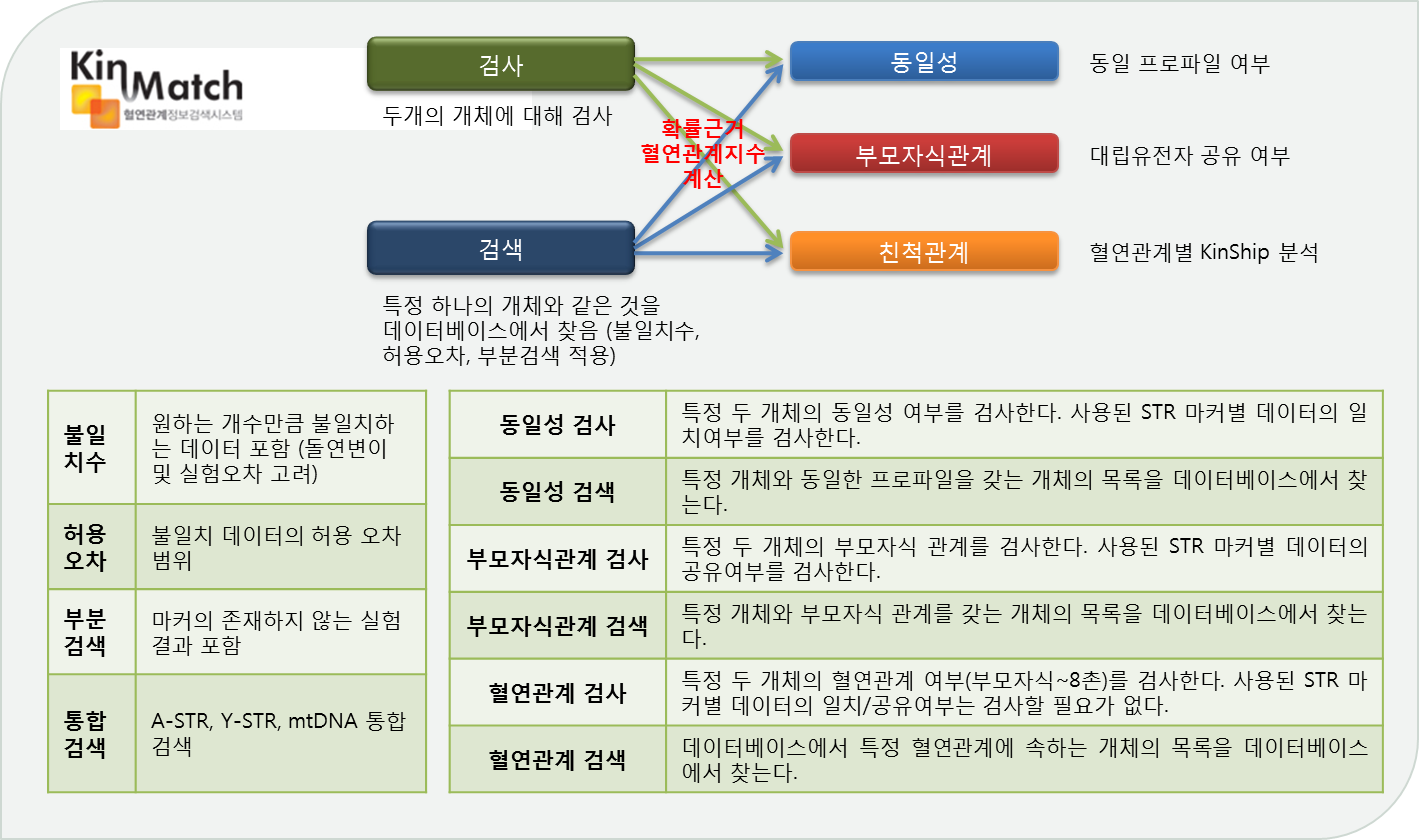
KinMatch는 대량의 DNA 유전정보로부터 개인(개체)간 혈연관계를 고속으로 검색하는 전문 검색엔진입니다. DNA는 부계, 모계 유전되므로 이것의 일치 혹은 공유 여부를 통해 부모자식관계, 친척관계를 확인하고, 정밀한 확률 통계분석으로 그 과학적 근거를 계산할 수 있습니다. KinMatch는 혈연관계 전문 검색엔진으로 A-STR, Y-STR, mtDNA SNP 등 비균일하고 다양한 DNA 유전정보 데이터로부터 빠르고 정확하게 혈연관계(동일성, 부모자식관계)를 검색하고 확률근거(혈연관계지수)를 계산합니다. 또한 불일치수 포함, 부분검색 옵션, 보고서 자동출력 기능 등을 제공하여 법의학분야 실무적인 활용성을 높혔습니다.
현재 국방부조사본부 “6.25전사자 DNA식별정보 검색시스템”, 국립과학수사연구원 “실종아동 등 찾기 DNA식별정보 검색시스템”, 축산물품질평가원 “쇠고기이력추적 통합정보시스템”에 성공적으로 통합되어 사용되고 있습니다.
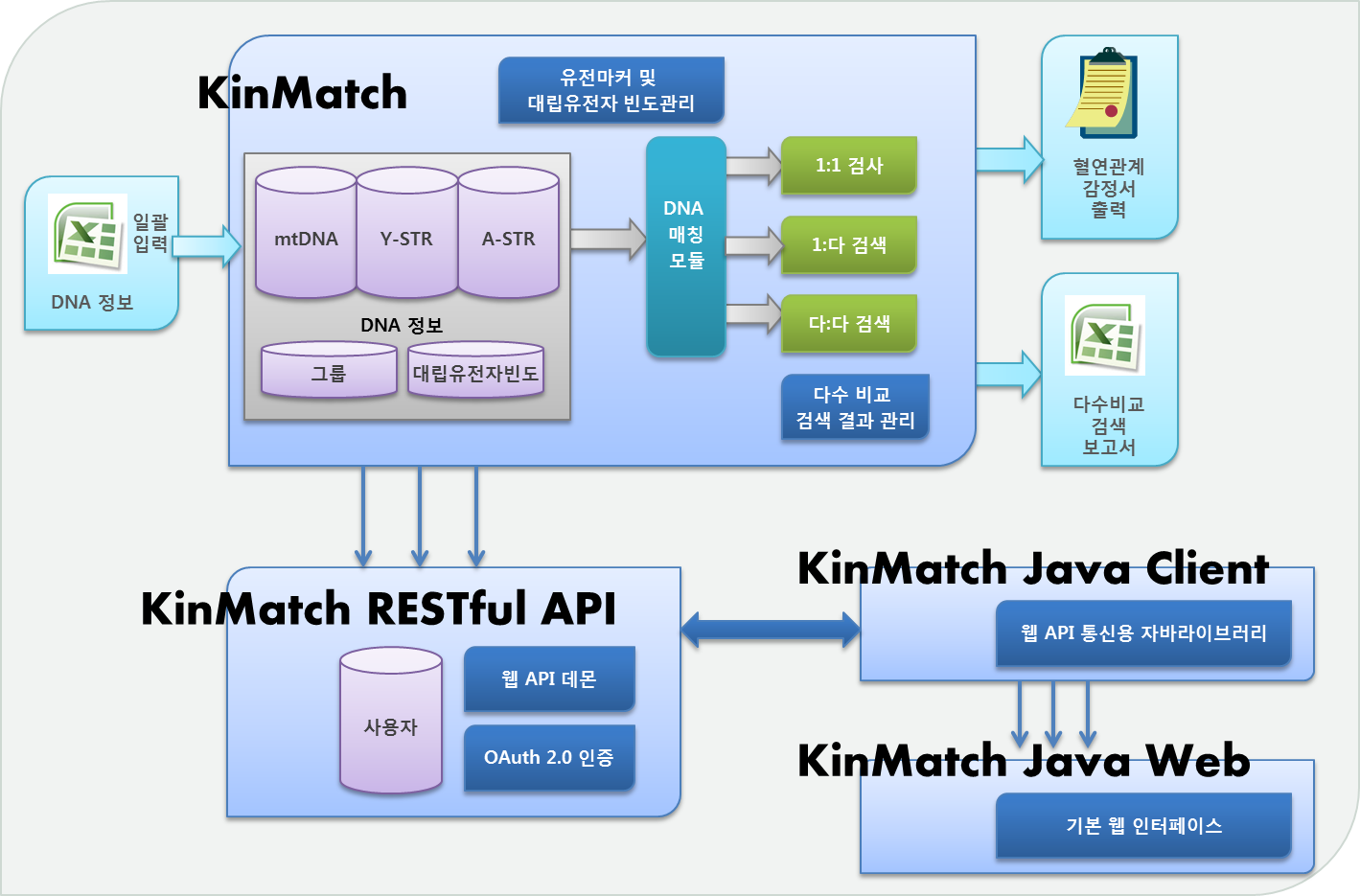
KinMatch v3은 세번째 업그레이드 버전으로 빠른 친척관계 검색이 가능하며, 코어엔진과 웹 API(RESTful), Java Client를 분리하여 다양한 환경에 효과적으로 통합됩니다.
1.3. 주요기능¶
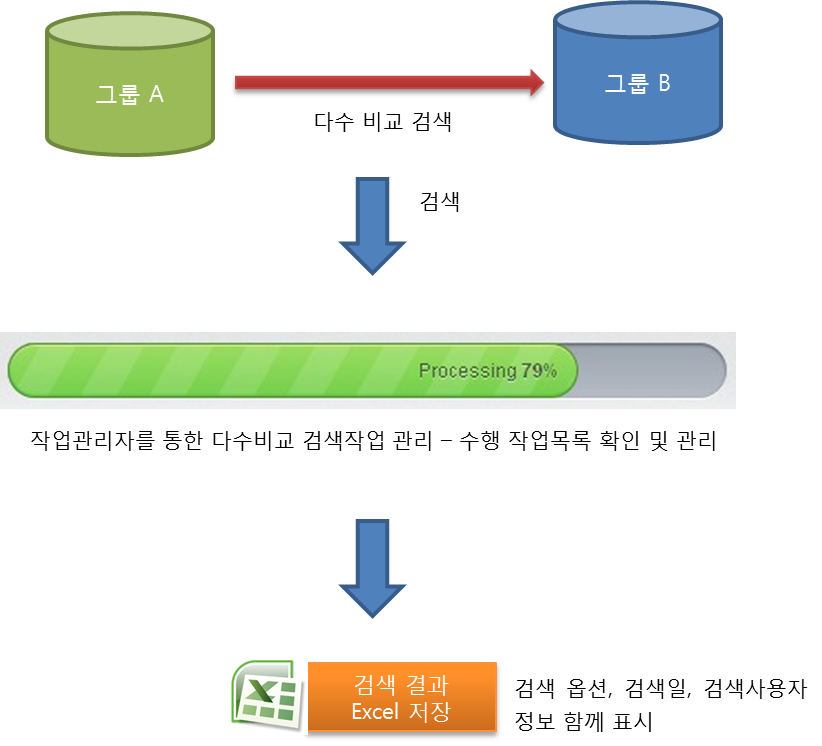
1.3.3. 다수비교검색¶
그룹간 전체 데이터에 대해 검색 (다수비교검색) 하는 작업은 데이터가 증가함에 따라 작업시간이 많이 소요될 수 있습니다. KinMatch는 검색작업관리(Task manager) 기능을 통해 수행중인 검색작업 목록을 보거나, 특정 작업을 중단하거나, 각 작업의 진척도를 확인할 수 있습니다.
다수비교검색결과는 Microsoft Excel 형식으로, 1:1 검사보고서는 아래한글 형식으로 제공되며, 맞춤형 템플릿을 지원합니다.
1.3.4. 대립유전자 빈도데이터 관리¶
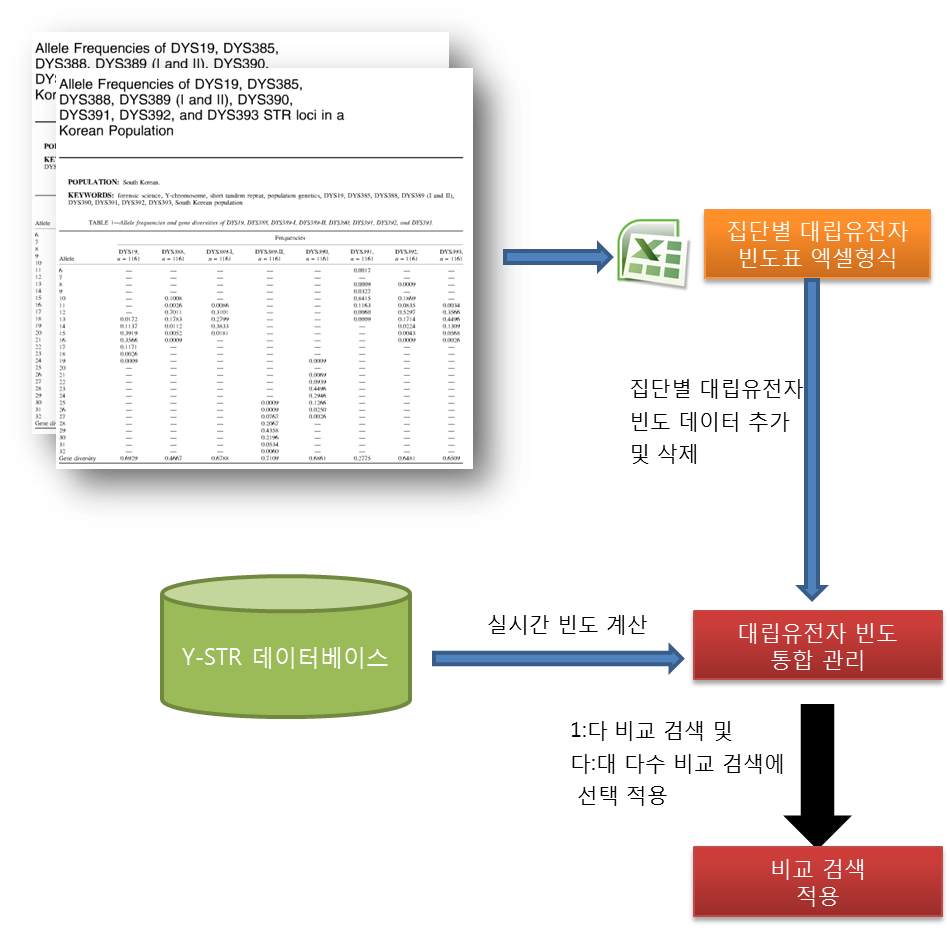
유전자 가족관계 검사 및 검색의 확률근거인 “혈연관계지수”를 계산하기 위해서는 특정 집단 (예, 한국인)의 대립유전자빈도표가 필요합니다. 이 데이터는 각종 법의학 연구논문으로부터 얻어지는데, KinMatch는 이를 직접 추가하고 관리할 수 있도록 지원합니다.
또한 현재 데이터베이스내 데이터를 이용하여 빈도표를 실시간 계산하고 이를 이용해 비교검색할 수 있는 기능을 별도로 제공합니다.
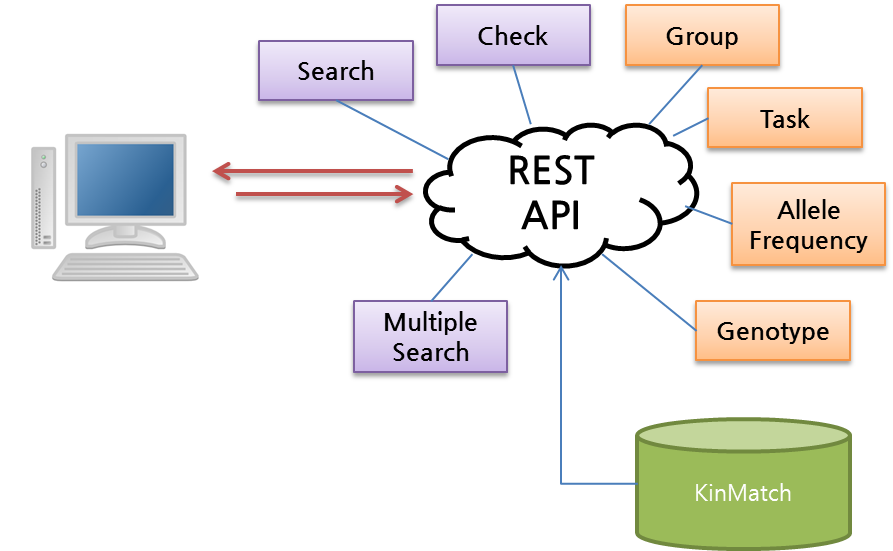
1.3.5. RESTful API¶
KinMatch는 다양한 실무환경을 지원하기 위해 RESTful API를 제공합니다. 4가지 KinMatch의 주요 리소스인 유전자형(Genotype), 대립유전자빈도(Allele frequency), 그룹(Group), 작업(Task)에 대해 CRUDL(Create, Read, Update, Delete, List) 인터페이스와 3가지 검색 API(검사, 검색, 다수비교검색)를 제공합니다.
OAuth2 기술을 이용하여 인증하며, 모든 데이터는 보안통신기술(SSL)로 보호됩니다.
자바환경 고객을 위한 별도의 KinMatch Java Client와 KinMatch Java Web 컴포넌트가 제공됩니다.