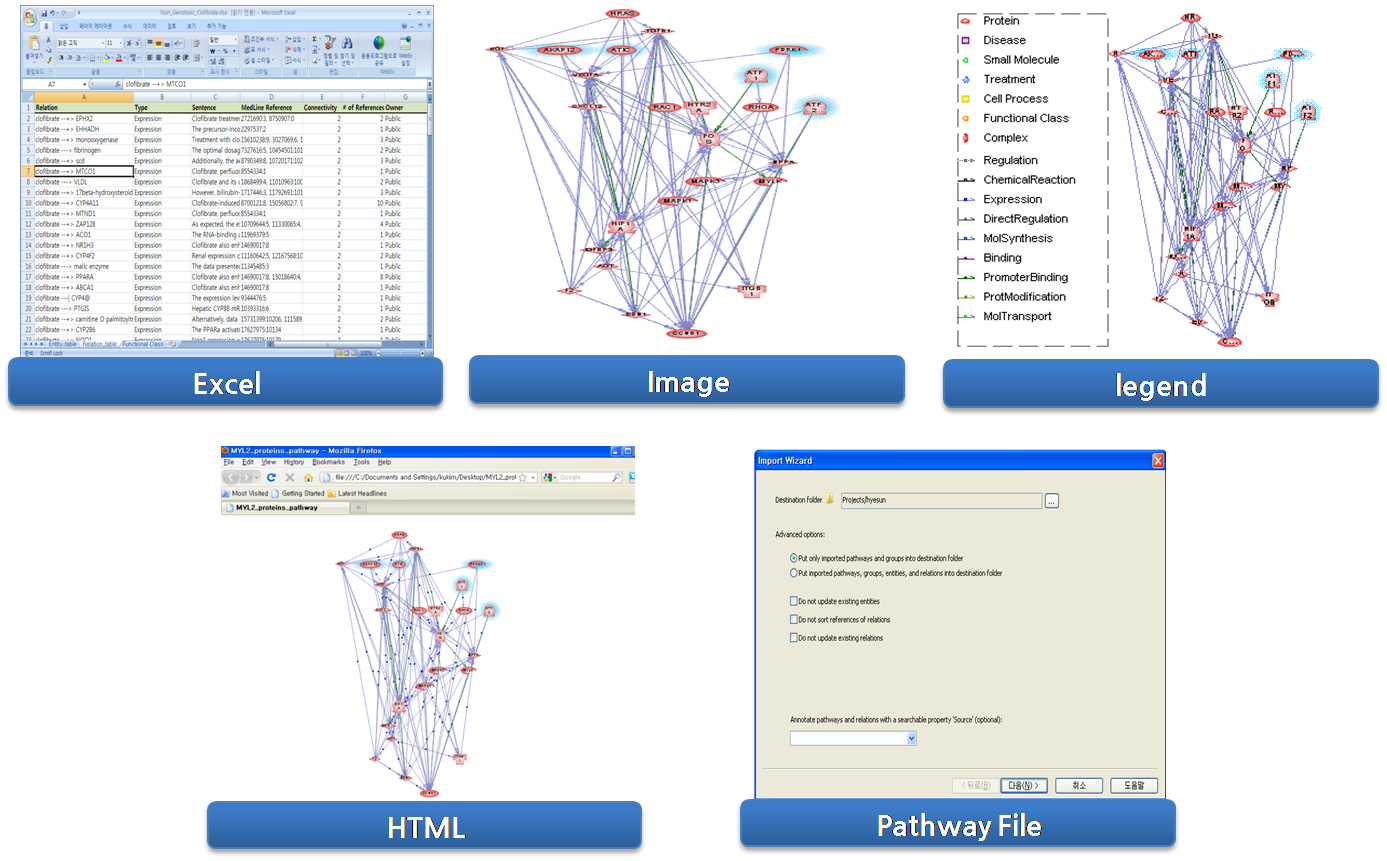
문헌정보를 활용한 유전자 네트워크 분석
- Posted at 2010/06/07 17:38
- Filed under 제품소식
연재 순서
1. PathwayStudio 소개
2. 문헌정보를 활용한 유전자 네트워크 분석
3. Chip 실험 데이터에서의 유전자 네트워크 분석
4. Drug 발굴을 위한 지식 데이터베이스 ChemEffect
MedScan의 필요성
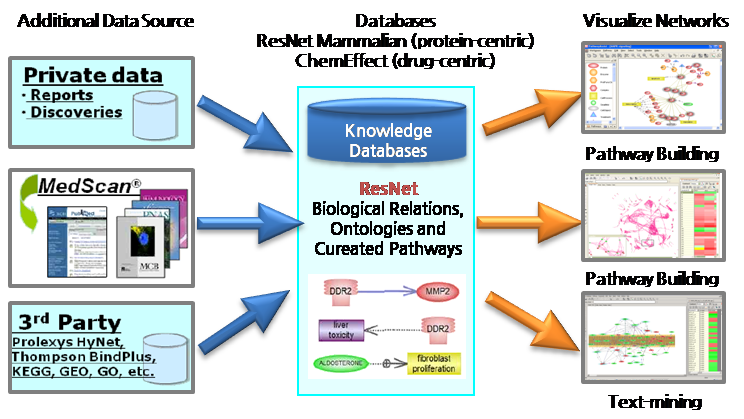
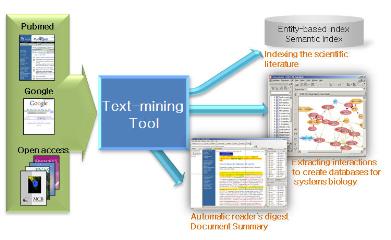
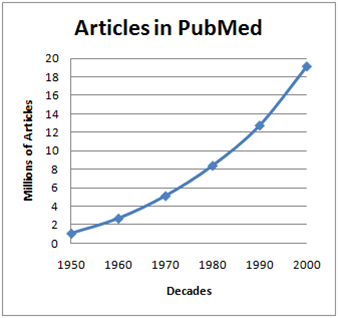
과학 문헌의 대표적인 데이터베이스인 NCBI의 PubMed는 시간이 지날수록 등록되는 문헌의 수가 급속도로 증가하고 있으며, 최근에는 약 1,900만건 이상의 문헌들을 서비스하고 있다. 즉, 증가의 추세로 볼 때 하루에 약 4,100여건의 문헌이 업데이트되고 있다. 문헌이 기하급수적으로 증가함에 따라 관련 연구에 대한 정보를 찾기 위해서 연구자들은 점점 더 많은 시간과 노력을 기울여야 한다. 이에 따라 문헌 속에서 생물학적인 정보를 자동으로 추출하는 시스템의 필요성이 증가하고 있다.
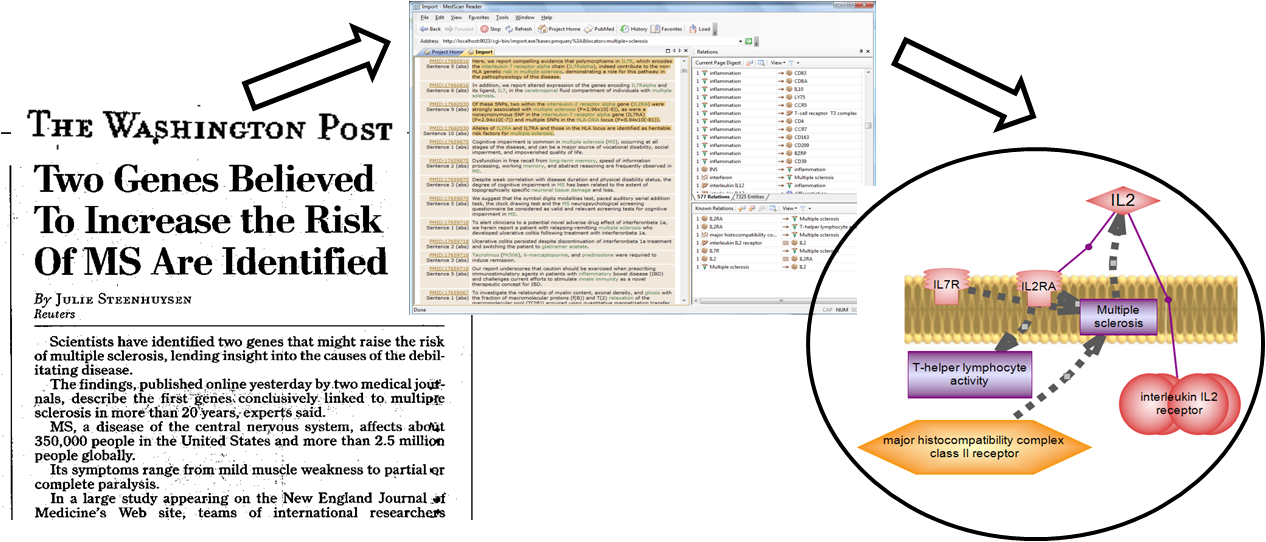
MedScan의 특징
이번 블로그에서는 PathwayStudio와 연계된 프로그램으로 PubMed, Google, 그리고 PDF, DOC 형식으로 된 문헌에서 텍스트 마이닝 기법으로 생물학적인 의미가 있는 데이터를 자동으로 추출하는 MedScan에 대해 소개하고자 한다. 데이터를 추출할 때 사용되는 텍스트 마이닝 기법은 복합 문서와 인터넷 페이지 등과 같은 비정형 데이터로부터 자연언어처리 기술과 문서처리 기술을 적용하여 유용한 정보를 추출하고 가공하는 기술을 말한다.
텍스트 마이닝 기법을 이용한 MedScan은
아래와 같은 특징들을 가지고 있다.
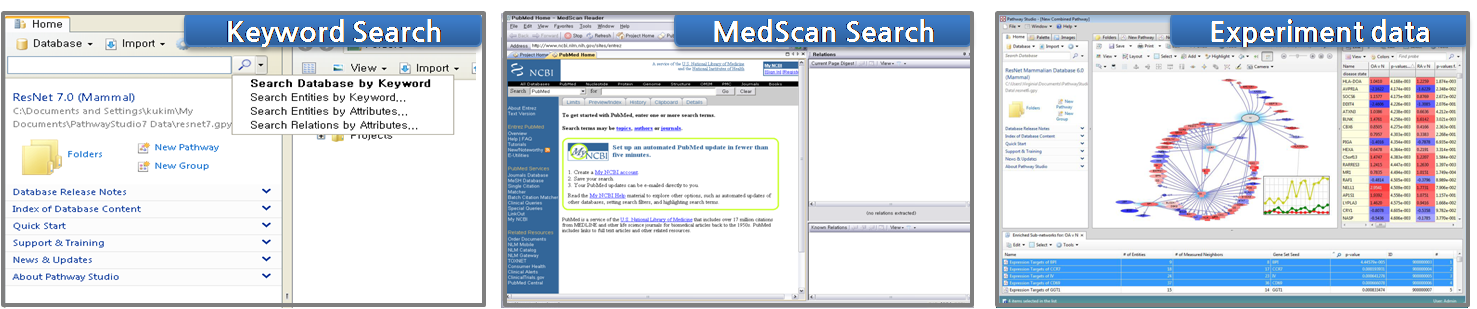
MedScan은 Pathway Sutido를 통해 실행시킬 수 있다. 실행된 화면은 그림 3에서 보는 것과 같이 사용자가 친숙하게 사용할 수 있도록 인터페이스가 구성되어 있다. MedScan에 서 문헌을 검색하기에 앞서 먼저 Catridge를 선택한다. Human, Mouse, Rat과 같은 mammal에 대한 검색을 할 때에는 Standard catridge를 선택하고, Plant와 관련된 검색을 할 때에는 Plant catridge를 선택한다. 간단하게 설정을 마치고 나면 검색을 수행할 수 있다.
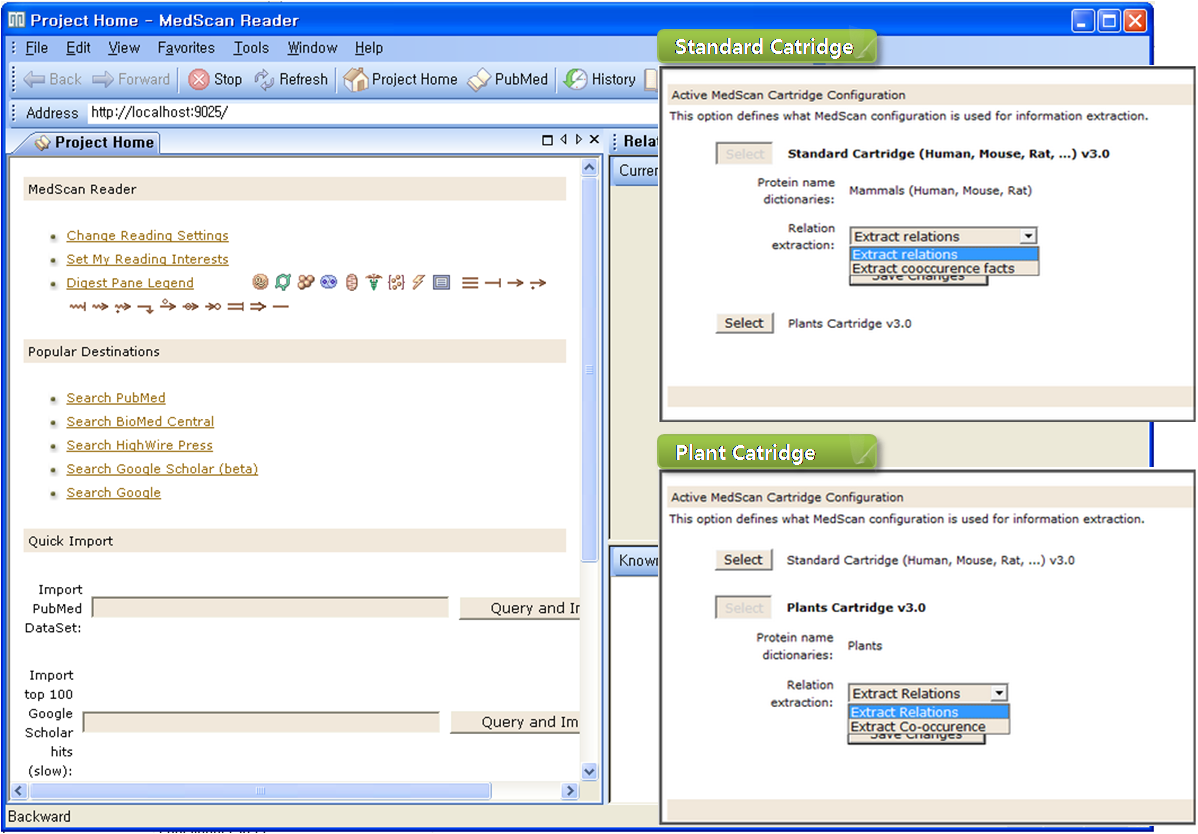 그림 3. MedScan
인터페이스.
그림 3. MedScan
인터페이스.
검색은 Popular Destinations과 Quick Import 두 가지 검색 방법을 이용한다. Popular Destinations에서는 Search PubMed, Search BioMed Central, Search HighWire Press, Search Google Scholar, Search Google 다섯 가지의 검색 할 수 있는 destination(그림 4)이 제공된다. 각각을 클릭하면 MedScan에서 바로 웹 사이트로 연결이 되어 인터넷 창을 따로 띄우지 않고도 검색을 수행 할 수 있도록 되어 있다. Quick Import 검색은 웹 사이트로 직접 연결하여 데이터를 검색하는 것보다 조금 더 빠르고 편리한 방법이다. 웹사이트에 연결하지 않고 바로 쿼리를 입력할 수 있도록 되어 있어서 Import PubMed Dataset에 쿼리를 입력하고 Query and Import 버튼을 클릭하면 기본적으로 PubMed abstract에서 1000개까지의 abstract을 추출해 준다.
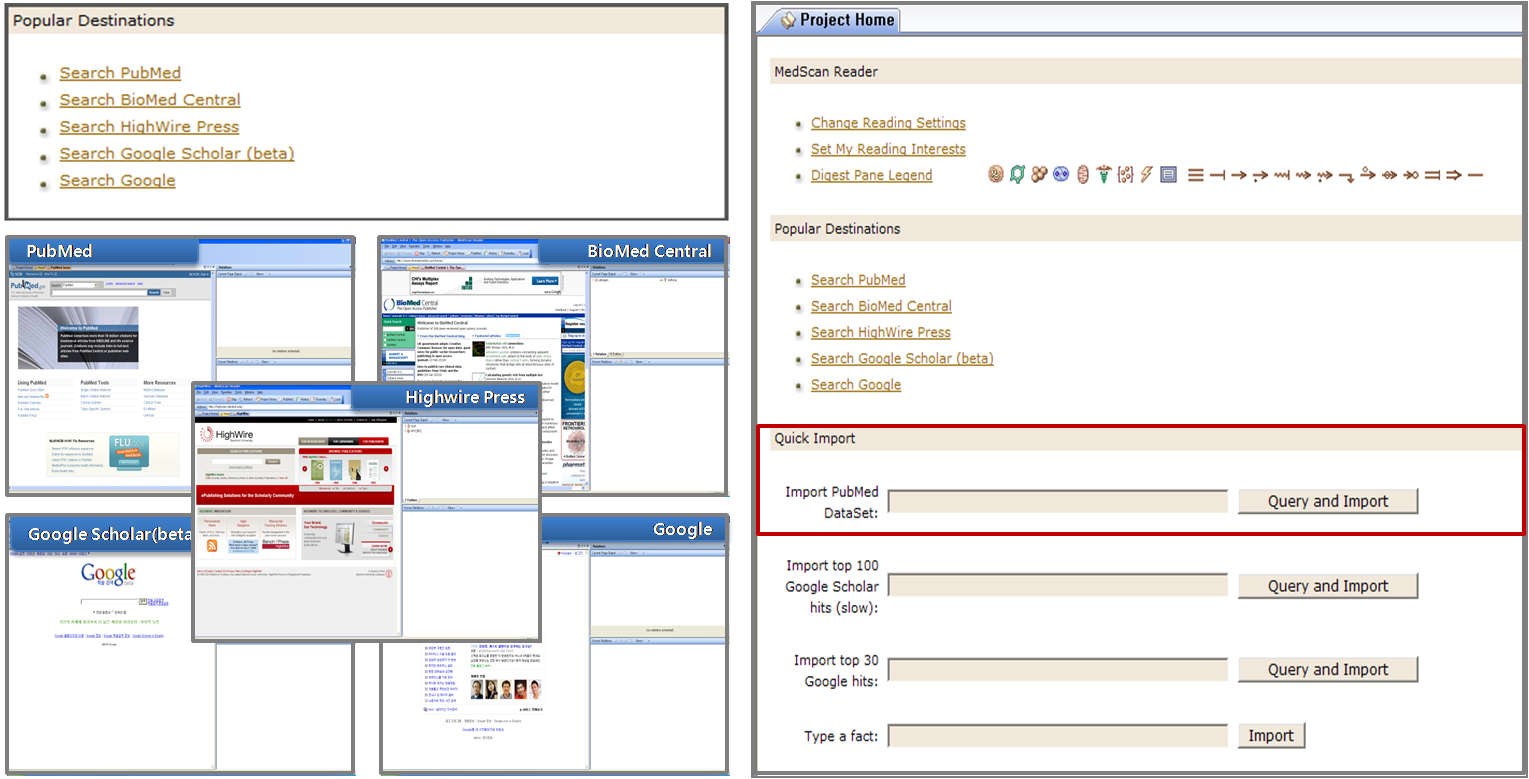 그림 4. MedScan
검색 방법. 1) Popular Destinations 2) Quick Import
그림 4. MedScan
검색 방법. 1) Popular Destinations 2) Quick Import
 그림 5. MedScan
검색 결과.
그림 5. MedScan
검색 결과.
- 생물학적인 문헌에서 정확하게 데이터를 추출할 수 있도록 과학적 언어에 Focusing
- 생물학 전문가에 의한 정보의 수정 및 Dictionary라고 정의된 Mammalian, Plant에 특화된 텍스트 마이닝
- 2분안에 918개의 abstract 다운로드, 7,700개 문장 리뷰, 7,300개 entity와 577개의 relation 관계 확인을 동시에 할 수 있을 정도의 빠른 속도
- 동일한 주제의 연구 정보에 대한 중복성 제거
- 생물학 전문가의 수정 및 지속적인 검증을 통한 10% 이하의 낮은 False positive 데이터
- Dictionary 및 검색 패턴을 연구자 의도에 따른 customization 가능
Tutorial
MedScan은 Pathway Sutido를 통해 실행시킬 수 있다. 실행된 화면은 그림 3에서 보는 것과 같이 사용자가 친숙하게 사용할 수 있도록 인터페이스가 구성되어 있다. MedScan에 서 문헌을 검색하기에 앞서 먼저 Catridge를 선택한다. Human, Mouse, Rat과 같은 mammal에 대한 검색을 할 때에는 Standard catridge를 선택하고, Plant와 관련된 검색을 할 때에는 Plant catridge를 선택한다. 간단하게 설정을 마치고 나면 검색을 수행할 수 있다.
문헌 검색
검색은 Popular Destinations과 Quick Import 두 가지 검색 방법을 이용한다. Popular Destinations에서는 Search PubMed, Search BioMed Central, Search HighWire Press, Search Google Scholar, Search Google 다섯 가지의 검색 할 수 있는 destination(그림 4)이 제공된다. 각각을 클릭하면 MedScan에서 바로 웹 사이트로 연결이 되어 인터넷 창을 따로 띄우지 않고도 검색을 수행 할 수 있도록 되어 있다. Quick Import 검색은 웹 사이트로 직접 연결하여 데이터를 검색하는 것보다 조금 더 빠르고 편리한 방법이다. 웹사이트에 연결하지 않고 바로 쿼리를 입력할 수 있도록 되어 있어서 Import PubMed Dataset에 쿼리를 입력하고 Query and Import 버튼을 클릭하면 기본적으로 PubMed abstract에서 1000개까지의 abstract을 추출해 준다.
Popular Destination 검색 가운데 “Search PubMed”를 선택하면, NCBI의 PubMed와 동일한 화면을 볼 수
있다. NCBI의 PubMed에서
문헌을 검색할 때와 동일한 방법으로 알고자하는 쿼리를 입력하고 검색을 수행한다. PubMed에서 문헌을 검색할 때
Display Setting을 Abstract로 변환하고, 페이지당 보여지는 문헌의 개수를 200개로 변환하면 더욱 더 많은
정보를 추출할 수 있다는 것을 염두해두자. 검색된 Abstract에서 검색하고자 했던 쿼리와 관련이 있는 정보들이 있는 문장은
노란색 배경처리되어 표시되고 생물학적인 의미를 지니고 있는 단어는 초록색으로 표시가 된다. 표시가 된 부분은 자동으로
Entity와 Relation으로 추출되어 우측 상단의 테이블 형태로 정리가 된다.
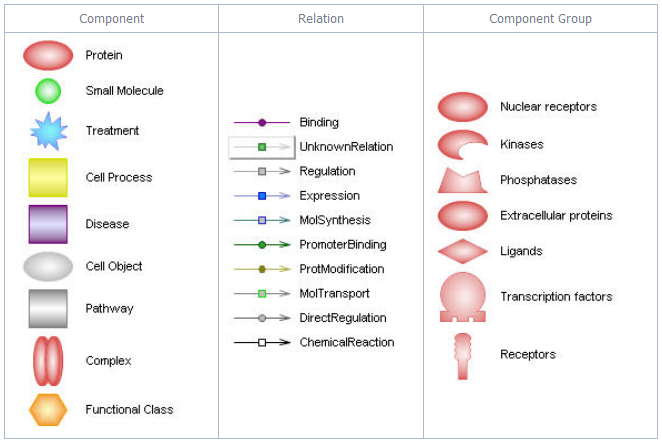
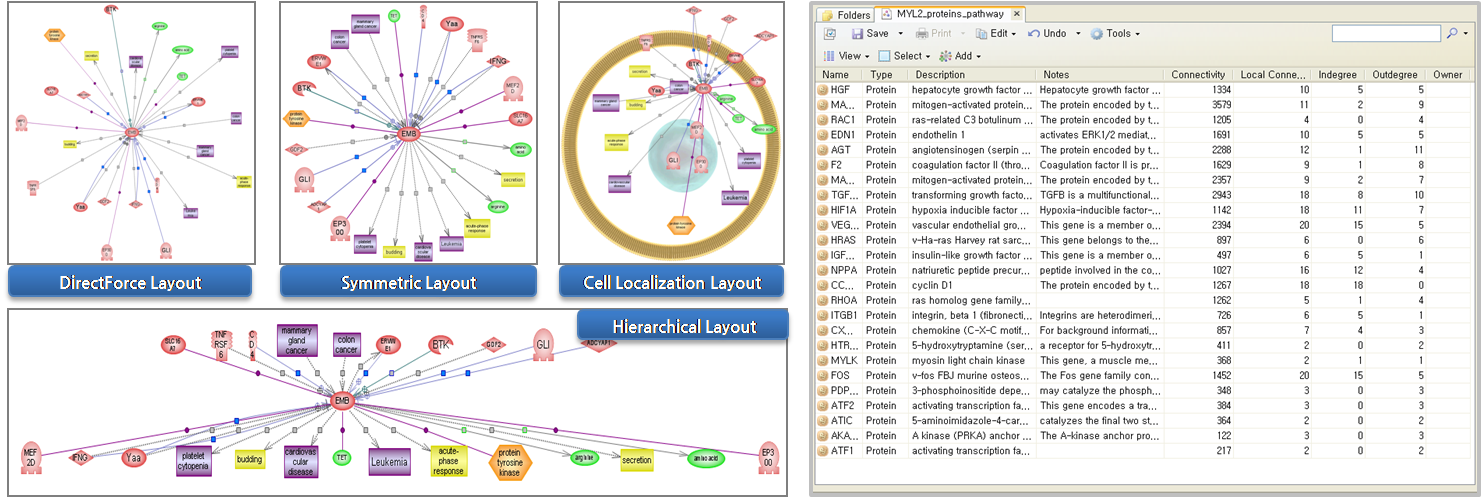
검색 결과가 정리된 우측의 테이블은 Relation tab과 Entities tab 두 가지 tab으로 결과가 정리되어 있다. Relation tab을 보면 첫 번째 컬럼은 Reference 문헌의 개수를 의미하고 두 번째 컬럼은 Entity 1, 세 번째 컬럼은 Relation 관계 정보를 마지막 네 번째 컬럼은 Entity 2를 나타낸다. 상단 도구모음의 View를 클릭하면 데이터를 컬럼별로 정렬하여 볼 수 있도록 되어 있다. 각각의 컬럼을 정렬해가면서 원하는 데이터만 키보드의 Shift 또는 Ctrl을 사용하여 선택한다. 그런 다음 선택된 데이터만 아래의 Known Relation 테이블로 이동시킨다. Known Relation 테이블에서도 다시 한 번 view를 통해 정렬을 하여 컬럼을 선택 할 수 있다.
그렇게 해서 최종적으로 선택된 데이터들만 가지고 Pathway Studio로 이동시킨다. 선택된 데이터에서 마우스 오른쪽을 누른 뒤 send to pathway studio 클릭한다. Pathway Studio를 다시 실행 시켜 보면 MedScan에서 보낸 데이터를 Import 할 수 있는 창이 떠있고 여기에서 pathway를 저장 할 디렉토리를 선택해주고 Next를 클릭한다. Import가 완료되고 해당 디렉토리로 가면 MedScan에 서 보낸 데이터 정보를 이용하여 그려진 pathway 파일이 생성되어 있는 것을 확인 할 수 있다.
검색 결과
검색 결과가 정리된 우측의 테이블은 Relation tab과 Entities tab 두 가지 tab으로 결과가 정리되어 있다. Relation tab을 보면 첫 번째 컬럼은 Reference 문헌의 개수를 의미하고 두 번째 컬럼은 Entity 1, 세 번째 컬럼은 Relation 관계 정보를 마지막 네 번째 컬럼은 Entity 2를 나타낸다. 상단 도구모음의 View를 클릭하면 데이터를 컬럼별로 정렬하여 볼 수 있도록 되어 있다. 각각의 컬럼을 정렬해가면서 원하는 데이터만 키보드의 Shift 또는 Ctrl을 사용하여 선택한다. 그런 다음 선택된 데이터만 아래의 Known Relation 테이블로 이동시킨다. Known Relation 테이블에서도 다시 한 번 view를 통해 정렬을 하여 컬럼을 선택 할 수 있다.
그렇게 해서 최종적으로 선택된 데이터들만 가지고 Pathway Studio로 이동시킨다. 선택된 데이터에서 마우스 오른쪽을 누른 뒤 send to pathway studio 클릭한다. Pathway Studio를 다시 실행 시켜 보면 MedScan에서 보낸 데이터를 Import 할 수 있는 창이 떠있고 여기에서 pathway를 저장 할 디렉토리를 선택해주고 Next를 클릭한다. Import가 완료되고 해당 디렉토리로 가면 MedScan에 서 보낸 데이터 정보를 이용하여 그려진 pathway 파일이 생성되어 있는 것을 확인 할 수 있다.
이밖에도 MedScan에서는 직접
사용자가 가지고 있는 텍스트, 워드, pdf, XML 또는 HTML 포맷의 문서를 Import 하여 데이터를 추출 할 수도
있다. Import 할 문서가 한 개 이상일 때에는 문서를 하나의 폴더 안에 저장해 놓고 폴더 자체를 Import 할 수도 있다.
우리가 어떤 연구를 하기 전에는 보통 문헌에서 내가 하고자 하는 연구가 어느 정도 선행 연구가 이루어 졌는지 알아보는데 그
때마다 많은 문헌들을 하나 하나 살펴 보기에는 어려움이 있다. 그 때 MedScan을 사용하면 그런 점에서
많은 도움을 줄 뿐만 아니라 그 문헌들 사이에서 의미 있는 결과까지 도출해 줄 수 있으리라 생각된다.
Posted by 人Co
- Tag
- ChemEffect, Chip 실험, Drug, insilicogen, MedScan, PathwayStudio, PubMed, Text-mining, 네트워크, 데이터베이스, 문헌정보, 유전자, 인실리코젠, 텍스트마이닝
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/75