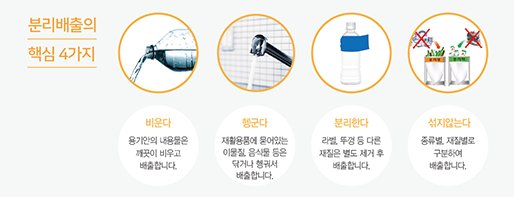
그동안 인코 블로그를 많이 사랑해주신 여러분께 진심으로 감사의 말씀을 올립니다.
2008년 5월에 시작된 인코 블로그는 2021년인 지금까지 여러분들의 관심과 성원으로 나날이 발전할 수 있었습니다.
2008년부터 2021년 현재까지 작성된 글은 374개나 된답니다~ 올해만 해도 1월부터 9월까지 총 55,000분이 방문해주셨는데요!
조회된 페이지 수도 75,000페이지에 달한답니다!
하지만 조금 더 많은 분들의 참여와 소통이 가능할 수 있도록,
또 모바일에 최적화된 블로그를 제공해드리기 위하여
2021년 10월 1일부터 Tistory로 블로그를 이전하게 됨을 알려드립니다.
기존 블로그는 유지되지만 앞으로 인실리코젠의 모든 소식은 이전하는 Tistory를 이용해 주시면 감사하겠습니다!
새롭게 단장된 Tistory에서 더 유익한 정보로 찾아뵙도록 하겠습니다~
아래의 링크를 클릭하시면 새로운 인코 블로그로 이동됩니다!
그동안 인코 블로그를 많이 사랑해주셔서 진심으로 감사드립니다!
더욱더 발전하는 인실리코젠이 되겠습니다.
감사합니다!
신규 블로그 바로가기: https://blog.insilicogen.com/
Posted by 人Co
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/393





 입사지원서_성명_지원부문_20210800.docx
입사지원서_성명_지원부문_20210800.docx