연말정산 납부세액 계산방법 소개
- Posted at 2021/02/20 23:48
- Filed under 정보공유

대한민국 직장인이라면 매년 진행하는 것이 있습니다. 바로 연말정산입니다.
연말정산을 통해 나온 납부세액이 잘못 나온 게 아닌가 하는 의문을 가진 경험도 한 번쯤은 있으실 겁니다. 번거롭기도 하고 규정과 상황이 항상 똑같을 수 없으므로 직접 납부세액을 계산하는 것은 어려울 수밖에 없습니다.
이 어려움을 조금은 극복하는 데 도움을 드리고자 오늘 블로그는 납부세액을 계산하는 전반적인 흐름을 소개하고자 합니다.
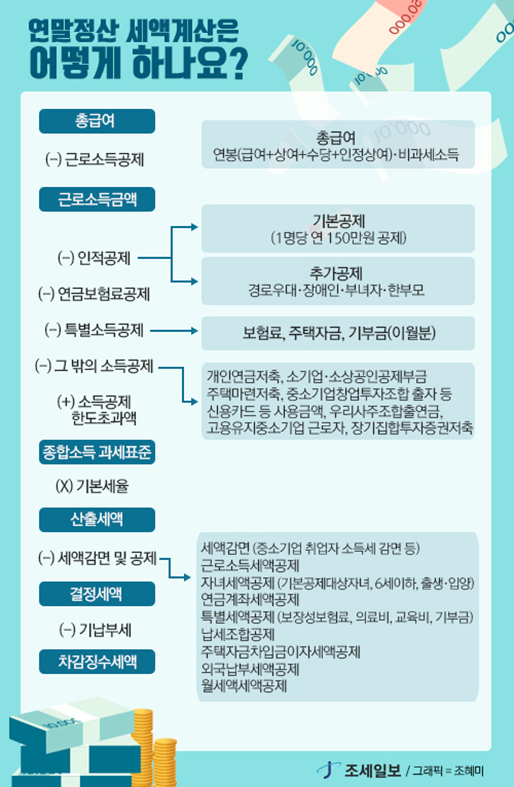

1. 총급여액 : 연봉(급여+상여+수당+인정상여)
2. 비과세소득

3. 근로소득공제
|
총급여액(인정상여 포함) |
근로소득공제(공제한도: 2,000만 원) |
|
500만 원 이하 |
총급여액 * 70% |
|
500만 원 초과 1,500만 원 이하 |
350만 원 + (총급여액 - 500만 원) * 40% (또는 150만 원 + 총급여액 * 40%) |
|
1,500만 원 초과 4,500만 원 이하 |
750만 원 + (총급여액 - 1,500만 원) * 15% (또는 525만 원 + 총급여액 * 15%) |
|
4,500만 원 초과 1억 원 이하 |
1,200만 원 + (총급여액 - 4,500만 원) * 5% (또는 975만 원 + 총급여액 * 5% |
|
1억 원 초과 |
1,475만 원 + (총급여액 - 1억 원) * 2% (또는 1,275만 원 + 총급여액 * 2% |

- 종합소득공제
- 기본공제: 1인당 150만 원
- 인적공제

- 추가 공제
-
추가공제 항목
공제요건
공제금액
경로우대자공제
70세 이상인 경우(1950.12.31. 이전 출생자)
1인당 연 100만 원
장애인공제
장애인인 경우
1인당 연 200만 원
부녀자공제
당해 거주자(종합소득금액이 3천만 원 이하) 본인이
*배우자가 있는 여성인 경우
*배우자가 없는 여성으로서 부양가족이 있는 세대주인 경우연 50만 원
한부모소득공제
배우자 없는 거주자로서 기본공제대상자인 직계비속 또는 입양자 있는 경우
연 100만 원
- 연금보헙료공제 : 원천징수의무자(회사)가 급여에서 일괄 공제 (별도 신청 X)
- 특별소득공제
- 건강·고용보험료 : 원천징수의무자(회사)가 급여에서 일괄 공제 (별도 신청X)
- 주택자금 :
-
공제종류
주택규모
공제금액
한도액
주택임차자금차입금
원리금상환공제액국민주택 이하
(주거용 오피스텔 포함)원리금 상환액 * 40%
상환기간 10년 이상 300만 원 한도
상환기간 15년 이상 연 500만 원 한도
고정금리 및 비거치식 기준에 따라 변동될 수 있음.장기주택저당차입금
이자상환액 공제제한없음(주거용 오피스텔 제외).
이자상환액
상환기간 10년 이상 이자상환액
상환기간 15년 이상 연 500만 원 한도
고정금리 및 비거치식 기준에 따라 변동될 수 있음. - 조특법상 소득공제
- 주택마련저축공제
- 공제한도: 저축불입액 * 40%
- 한도액: 2,500만 원
신용카드 등 공제(2020년 한정)
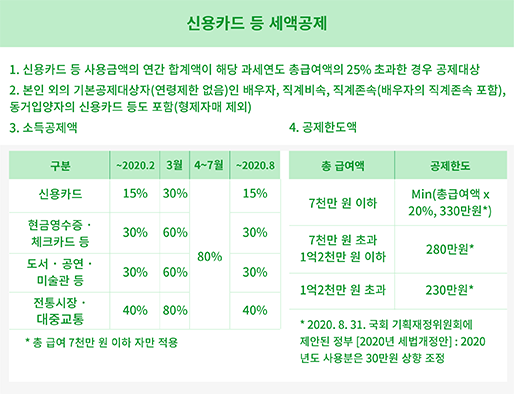
- 기존 신용카드 등 공제율
-
구분
공제율
신용카드
15%
현금영수증·체크카드 등
30%
도서·공연·미술관 등
30%
전통시장·대중교통
40%
- 산출세액 = 과세표준 * 세율
-
과세표준
세율
1,200만 원 이하
과세표준*6%
1,200만 원 초과~4,600만 원 이하
과세표준*15%-108만 원
4,600만 원 초과~8,800만 원 이하
과세표준*24%-522만 원
8,800만 원 초과~1억5천만 원 이하
과세표준*35%-1,490만 원
1억5천만 원 3억 원 이하
과세표준*38%-1,940만 원
3억 원 초과 5억 원 이하
과세표준*40%-2,540만 원
5억 원 초과 10억 원 이하
과세표준*42%-3,540만 원
10억 원 초과
과세표준*45%-6,540만 원

- 근로소득세액공제
-
근로소득에 대한 산출세액
근로소득세액공제
130만 원 이하
산출세액 * 55%
130만 원 초과
715,000원 + (130만 원 초과 산출세액) * 30%

- 자녀세액공제
- 기본공제대상 자녀(손자·손녀 제외)로서 7세 이상의 자녀 수에 따라 세액공제
- 1인: 연 15만 원 / 2인: 연 30만 원 / 3인 이상: 연 30만 원 + 2인 초과 1인당 30만 원
- 출산·입양공제
- 첫째 연 30만 원 / 둘째 연 50만 원 / 셋째 이상 연 70만 원
- 기본공제대상 자녀(손자·손녀 제외)로서 7세 이상의 자녀 수에 따라 세액공제
- 월세세액공제: 세액공제액 = Min(월세액, 750만 원) * 10%특별세액공제
- 무주택 세대의 세대주인 근로자
- 총급여액 7천만 원 이하로서(종합소득금액 6천만 원 초과자 제외)
- 국민주택규모주택 또는 기준시가 3억 원 이하인 주택(주거용 오피스텔, 고시원 포함)에 대한 월세





결정세액과 기납부세액을 비교하여 (+)인 경우 납부 (-)인 경우 환급
- 기납부세액: 종합소득공제 중 연금보험료공제, 건강·고용보험료공제 등 매월 원천징수한 세액

이혼 시 재산분할? 위자료 청구? 세금에서는 어떤 것이 더 유리할까요??
재산의 양도로 발생하는 이익(소득)에 대해서 양도소득세가 부과되는데 부부가 이혼하여 재산분할이나 위자료 지급 또한 재산의 양도로 구분이 됩니다.
- 재산분할의 경우 : 양도소득세가 부과되지 않습니다.
- 이혼하면서 재산분할을 원인으로 부동산을 이전하는 경우 양도소득세나 증여세가 부과되지 않습니다.
- 이혼재산분할은 부부가 공동으로 이룩한 재산에 대한 청산의 관점으로 보기 때문에 재산을 양도하는 것이나 증여하는 것은 아니라고 보기 때문입니다.
- 위자료의 경우 : 부동산양도의 경우 양도소득세가 부과됨
- 위자료를 금전으로 지급하는 경우에는 세금이 문제 되지 않지만, 위자료의 명목으로 부동산을 이전하는 경우 양도소득세가 부과될 수 있습니다.
- 위자료 명목으로 부동산을 이전하는 것은 일정액 상당의 위자료 지급의무를 소멸시키는 경제적 이익을 얻는 양도에 해당하여 양도소득세가 부과되는 것입니다.
물론 이혼할 일이 없어야겠지만 이런 상황에 세금마저 내야 한다면 억울하겠죠. 사정에 따라 다르겠지만, 부부간 재산을 정리할 때는 세금도 고려해서 본인에게 이익되는 방향으로 진행하시기 바랍니다.

연말정산 절차가 간소화되어가며 직접 연말정산 납부세액을 계산하는 일은 확연히 줄었습니다. 실제 계산을 하기 위함보다는 나의 납부세액이 어떻게 결정되느냐의 전반적인 흐름을 파악하는 것을 통해 놓칠 수 있는 세액공제나 세액감면 등의 혜택을 받을 수 있다고 생각합니다.
Posted by 人Co
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/371


 [Fig. 1] 전주한정식
[Fig. 1] 전주한정식