
인공지능(AI, 기계학습) 공부에 도움될 사전 지식 및 사이트
- Posted at 2019/12/05 16:39
- Filed under 정보공유

4차 산업혁명이라는 이름에 걸맞게 생물 분야 뿐만 아니라 어느 도메인에 가도 AI란 용어를 어렵지 않게 찾을 수 있어요. 연구소나 기업은 현재 진행하는 프로젝트에 AI를 접목해 기계학습 및 프로그래밍을 활용하고 있습니다. 덕분에 기존 Rule-based의 작업이 해결하지 못했던 부분까지 많은 인력을 쓰지 않고도 높은 정확도의 프로세스를 진행할 수 있기도 합니다. 그렇다면 AI 분야 특히, 기계학습 혹은 딥러닝(기계학습의 부분집합)에 입문하는 우리는 무엇을 준비해야 할까요?
블로그를 쓰고 있는 현재에도 이 분야와 직・간접적으로 관련된 기초를 탄탄히 하고자 공부하고 있는 사람으로서 AI를 이해하기에 필요한 사전 지식과 그에 도움이 될 만한 좋은 책, 사이트, 세미나 강좌들을 선별하여 소개하려 합니다. 공부 순서는 크게 상관없고요. 기계학습 및 딥러닝을 공부하다가 언젠가 필요해질 때, 이 블로그에 찾아오셔서 방향을 찾아보는 것도 좋은 방법이 될 것으로 생각합니다.

연구 분석가나 개발자는 프로그래밍 언어는 필수적으로 하나 정도는 쓸 수 있어야 합니다. 언어는 다양하지만, 일의 목적에 따라 적합한 언어가 다를 수 있습니다. 기계학습 및 딥러닝 분야에서는 R과 Python이 현재 많이 쓰이고 있어서 개발된 라이브러리를 편하게 이용하기 위해선 둘 중 하나를 추천합니다. 참고로 전 Python을 주로 쓰고 있기에 아래 대부분의 포스팅은 Python에 맞춰져 있습니다.

책으로 사도 되지만 온라인에 e-book으로 있어서 언제든 참고 가능합니다. 첫 장부터 재미있다고 최면을 걸고 끝까지 한번은 정독하시길 권장 드려요. 후반부에 점차 어려울 순 있겠지만, 독학이 어려운 수준은 절대 아닙니다.
도전! (점프투파이썬)
Linux 기초와 파이썬 및 Pandas 교육(인실리코젠)
우리 회사에서는 Bio 분석가를 위한 교육이 매달 진행되고 있습니다. 달마다 주제가 달라지지만, Linux 기초와 파이썬 및 Pandas 교육도 있습니다. 책이나 강좌로 차근히 배우는 것도 좋지만, 이런 교육을 활용하면 단시간 내에 컴팩트한 기초문법 및 활용을 접할 수가 있습니다. 하지만 교육 수련생의 자릿수가 정해져 있으니 미리 홈페이지와 페이스북 알림을 통해 확인해보시길 추천합니다.

- 人CoACADEMY : 생물정보 관련 교육 정보를 얻을 수 있음.
- 人CoDOM : 생물정보 분야의 집단 지성 창출을 목적으로 운영되는 지식 커뮤니티
- 인실리코젠 페이스북 : 친구를 맺어놓으면 관련 소식을 빠르게 받아볼 수 있음.
- KOBIC 교육센터 : 인실리코젠이 제작한 온라인 무료 교육(상시 오픈형 교육은아님.)

NumPy는 파이썬의 수학 라이브러리입니다. 라이브러리란 '이미 누군가가 잘 만들어놓은 패키지'로 자주 쓸 것 같은 특정기능을 모아놓은 함수를 의미합니다. 즉, 파이썬으로 코딩 시 수학 라이브러리(예를 들면 Sin(x), Cos(x) 등)를 직접 구현할 필요 없이 NumPy 안에 저장되어있는 함수들을 가져와 쓸 수 있다는 거죠. 수학 및 통계 라이브러리와 더불어 NumPy의 장점은 속도에 있습니다. 내부적으로 C와 Fortran으로 작성되어있어 실행속도가 일반적인 수준에 비해 꽤 빠른 편이죠. NumPy와 관련된 설명은 나무위키에 잘 정리되어있으니 한번 읽어보는 것도 좋겠네요. 또한, 많은 기계학습과 딥러닝 패키지가 NumPy를 기반으로 구현되어있고 input 및 인자 데이터 타입을 NumPy로 요구하기 때문에 꼭 익혀야 하는 모듈이기도 합니다.
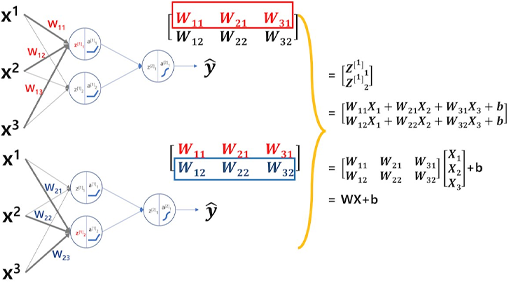
기계학습 및 딥러닝에서 왜 이걸 써야 할까요? 우선, 간단하게 행렬 연산에 대해 말해보겠습니다. 기계학습 및 딥러닝 내부적 알고리즘에선 내가 가진 데이터를 잘 설명하는 해(기울기 혹은 가중치)를 찾기 위해 다항식의 연립방정식을 풀 수밖에 없다는 건 공감하실 겁니다. 이런 일들이 시간상 효율적으로 이루어지려면 선형대수학을 이용하여 계산할 수밖에 없고, 그 말은 행렬식을 다뤄야 한다는 말이죠. 만약 기본 자료형인 리스트로 2차원 행렬을 만들게 되면 아래와 같습니다.
>a = [[1, 2], [3, 4]] >a [[1, 2], [3, 4]]
여기에 단순히 행렬 스칼라 곱을 하려 해도 이중 for 문을 써서 계산을 해야 하죠. 그러나 NumPy를 쓰면 행렬 연산을 지원하기 때문에 아래와 같이 아~주 간단히, 쉽고, 빠르게 계산진행이 가능합니다.
>import numpy as np
>a = np.array(a)
>a
array([[1, 2],
[3, 4]])
>a*2
array([[2, 4],
[6, 8]])이를 브로드캐스팅(broadcasting)이라 하고 하며, 작은 배열을 큰 배열과 서로 호환되도록 아래와 같이 작은 배열이 큰 배열에 크기를 맞추는 것입니다. 이런 편리한 기능이 있는데 당연히 NumPy를 쓸 수밖에 없겠죠?

나무위키 : https://namu.wiki/w/NumPy
딥러닝에서 자주 쓰이는 NumPy 상식 : https://sacko.tistory.com/51
NumPy 실습(아주 상세) : http://taewan.kim/post/numpy_cheat_sheet/

Matplotlib이란 시각화 라이브러리 중 하나입니다. 만약 R 언어를 이용하고 있다면 ggplot이란 강력하고 대표적인 라이브러리가 있겠네요. Python에서도 대표적인 하나를 뽑자면 Matplotlib이 있습니다. 그러나 다른 라이브러리보다 이것을 꼭 이용해야 한다고 말하고 싶은 건 아닙니다. Python에선 Matplotlib을 포함하여 seaborn, plotly 같은 고차원 그래픽 모듈도 있으므로 분석가의 목적 또는 기호에 따라 다양하게 이용할 수 있어요. 많은 모듈 중 손쉽게 시각화를 구현할 수 있는 하나 라이브러리를 익혀두는 게 좋습니다.
시각화 모듈은 기계학습 및 딥러닝에서 정말 많이 쓰시게 될 겁니다. EDA(Exploratory Data analysis, 탐색적 데이터 분석) 작업을 하다 보면 데이터 전체의 분포를 보기 위해서는 테이블보다 그림(박스플롯, 산점도)이 강력한 도구가 되기도 합니다.
또한, 이미지 딥러닝 중 segmentation을 예로 들어보면, 내가 생성한 모델의 prediction accuracy가 얼마나 높게 나타나는지 보고 싶을 때가 있을 겁니다. Image processing 기법과 시각화 모듈을 사용하면 원본 이미지와 결과 이미지를 시각화하여 overlap 해보면 모델이 좋은 방향으로 개발되고 있는지 확인도 가능하겠네요.

Deeplearning - segmentation model
Matplotlib 튜토리얼 : https://matplotlib.org/1.3.1/users/pyplot_tutorial.html
인코덤-Matploblib : https://www.incodom.kr/파이썬/라이브러리/Matplotlib

드디어 Pandas 입니다. 역시나 파이썬의 모듈이고요. 이게 뭔지 가장 잘 표현하는 방법은 R의 vector와 dataframe 기능입니다 라고 설명하는 것입니다. R을 접해보시지 않은 분들을 위해 부가 설명해드리면 이 언어는 Wes McKinney가 '시계열 데이터를 분석하기 위해 Python도 R과 같은 데이터 분석이 가능한 모듈이 필요해'라고 생각해서 만든 모듈입니다. 따라서 당연히 R을 닮았습니다. 기본 Python으로 코딩한다면 테이블 형식의 데이터를 행과 열을 추출하고, 혹은 특정 조건을 걸어 추출하고 새로운 테이블 형태로 정리하는…. 말로만 해도 얼마나 많은 번거로움이 나타날지 느껴지시죠?
간단한 예제를 통해 확인해볼게요. 예제를 볼 땐 이걸 순수 Python으로 코딩해서 똑같은 작업을 한다면 몇 줄에 끝낼 수 있을지 상상해보면서 보도록 합시다. 우선 csv 예제 파일을 읽어서 데이터 구조부터 파악해 볼게요.
※첨부파일 : train.csv
>import pandas as pd
>train = pd.read_csv('train.csv')
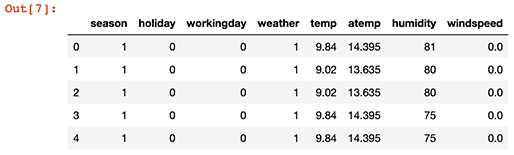
>print(train.columns)
Index(['datetime', 'season', 'holiday', 'workingday', 'weather', 'temp',
'atemp', 'humidity', 'windspeed', 'casual', 'registered', 'count'],
dtype='object')
>train.head()
그럼 여기서 casual, registered, count, datetime 열만 삭제하고 새로운 데이터를 만들려면? Python만으로는 반복문과 변수선언 등등 여러 가지 방법들이 머릿속을 지나가죠. 그렇지만 pandas는 한 줄로 처리할 수 있습니다. 그 dataframe에서 간단히 plot 생성도 가능하고요.
train = train.drop(["casual", "registered", "count", "datetime"], axis=1) train.head()

Matplotlib같은 시각화 모듈과 함께 Pandas를 사용하면 아주 강력한 EDA툴이 되기도 합니다. 특히나 Mckinney의 의도처럼 시계열 데이터를 가공하고 EDA를 진행하는데 강력한 도구가 될 수 있답니다.
요즘엔 AI뿐 아니라 데이터 분석을 위해서 관련 교육이 늘어가는 추세가 보입니다. 특히 Jupyter + Pandas + maplotlib/seaborn 을 묶어서 교육을 진행하는 프로그램들이 점차 늘어나고 있습니다. 우리 인실리코젠의 외부 교육프로그램도 해당 주제를 다루고 있으니 페이스북을 통해서 교육 소식을 접하시고 필요하시면 신청하면 좋을 것 같습니다. 19년 08월에 진행한 교육 내용은 아래의 github을 참고 해주세요~
Website
inflearn(유료) : https://www.inflearn.com/course/%ED%8C%90%EB%8B%A4%EC%8A%A4-Pandas#
DATAQUEST-time series tutorial with pandas : https://www.dataquest.io/blog/tutorial-time-series-analysis-with-pandas
GitHub
- 인실리코젠 교육내용 및 자료 - Pandas
- 주제 : Linux 기초와 파이썬 및 Pandas 교육(인실리코젠)

구글의 코랩(Colab) 서버는 구글이 제공하는 Jupyter notebook입니다. 막상 기계학습과 딥러닝을 진행하려 하다 보면 적절한 환경부터 세팅이 안 되어 있거나, 가지고 있는 컴퓨터의 성능이 좋지 않아 시작부터 어려움을 느낄 때가 있습니다. 그러나 Colab을 이용하면 인터넷 환경만 갖춰진다면 어떠한 컴퓨터 심지어 태블릿으로도 실습이 가능해집니다. 구글 계정만 있으면 무료일 뿐만 아니라 딥러닝 구현 시 GPU도 몇 번의 클릭으로 연동할 수 있어서 연산속도도 빠르게 됩니다. 잘 만든 Jupyter는 그 자체만으로도 나만의 문서가 될 수 있으니, 시간이 될 때 잘 작성된 블로그나 문서를 보고 연습하시길 추천합니다.
(특징 : Jupiter notebook 환경 제공, 무료, GPU 사용 가능, 구글 드라이브와 연동 가능)
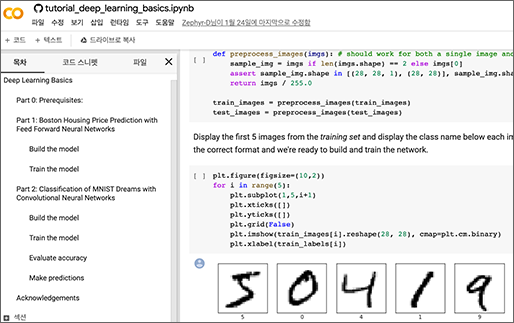

이 부분은 다른 파트와는 달리 완벽히 이론적인 부분입니다. 기계학습의 기원은 전산학, 컴퓨터 공학, 통계학 등 다양한 곳으로부터 발전했다고 합니다. 이는 결국, AI를 통찰하기 위해선 수학이 기본이 되어야 함을 이야기합니다. 얼마나 깊이 공부해야 하는가는 목표에 따라 다르겠지만, 세부적인 수식까진 아니더라도 전체적인 계산 흐름 정도는 알아야 해석할 수 있어야 자신의 데이터에 맞는 디버깅 또는 최적화가 가능하다 생각해요. 그러기 위해서는 앞서 언급한 통계학(기초통계학, 회귀분석, 선형대수학)과 미분학이 어느 정도 뒷받침되어주어야 합니다.
간단한 예를 들어 볼게요. 기계학습 및 딥러닝에선 손실함수(Cost function 혹은 Loss function)의 최소화가 목적입니다. 이때 주로 드는 예시가 MSE(Mean Squared Error, 평균제곱 오차)방법입니다.
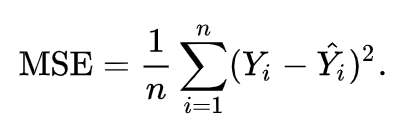
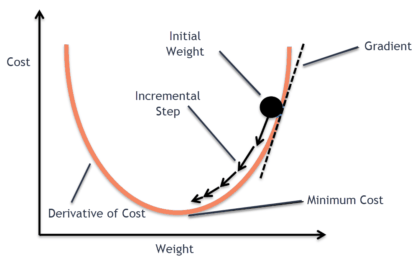
여기서 제가 생각한 것은 단지 과정의 흐름입니다. 실력이 좋으신 분은 손으로 직접 풀어가며 계산도 가능하겠죠. 하지만 그렇게까지는 아니어도 내부적인 흐름만 알더라도 기계학습이 한층 재미있어질 것입니다. 아무래도 전공이 아니라면 장벽이 있고 범위도 넓어 어려움이 있겠지만, 그때마다 관련 강의나 책을 찾아보면서 차근히 익혀나가길 추천해 드려요.
통계가 완전 처음이 아니라면 전 Gareth James 저자의 ISL(An Introduction to Statistical Learning)을 추천합니다. 기계학습 입문 이론서 중 유명하고 인기가 있습니다. 아래 사이트에서 PDF를 내려받을 수 있고요(물론…. 영어지만요). 2016년에는 '가볍게 시작하는 통계학습'이란 번역서로 출판하기도 했습니다.
Website & PDF교재
ISL study 블로그 : http://godongyoung.github.io/머신러닝/2017/12/30/ISL-study_plan.html
PDF교재 : ISL -기계학습 기본 통계 : http://faculty.marshall.usc.edu/gareth-james/

요즘 이미지와 관련된 분석들이나 자동화 기술은 CNN이 활발하게 이루어진 때부터 '모두 딥러닝 아니야?'라고 생각할 수도 있을 만큼 딥러닝 기술이 널리 이용되고 있어요. 그러나 좀 더 실생활 혹은 실용적인 프로젝트를 운영한다면 딥러닝 부분은 프로젝트 일부분이고 많은 부분이 이미지 프로세싱으로 접근 가능하다는 것을 알게 됩니다. 이미지 프로세싱은 말 그대로 사진 또는 영상에 여러 연산을 접목해 새로운 사진 및 영상을 얻어내는 기법을 뜻하는 데요. 화질 개선 및 복원, 영역 추출, 객체 검출, 회전, Perspective transformation 등 많은 이미지 처리 작업에 적용할 수 있습니다.


Website
당연히 전공이 아니라면 거부감이 있는 주제긴 하지만 어떠한 주제들이 있는지 이해하고 있는 것만으로도 딥러닝 관련 프로젝트를 더욱 완벽히 만들 수 있을 겁니다. 이미지 프로세싱을 위해선 scikit-image 또는 openCV라는 모듈이 가장 잘 알려진 모듈입니다. 아래 있는 사이트에서 예제와 내용을 꽤 자세히 설명해주고 있으니 다양한 주제를 접해보는 경험도 좋을 거라 생각됩니다.
OpenCV home : https://opencv-python.readthedocs.io/en/latest/
Scikit-image home : https://scikit-image.org/
마치며
인실리코젠에서 기계학습을 이용한 마커 선발과 모바일 이미지를 이용한 segmentation 딥러닝과 관련된 프로젝트에 참여하고 있다 보니 가끔 교육, 학회 및 워크숍에서 저에게 실무자 혹은 학생분들이 다음과 같은 질문을 하곤 했습니다.
- ‘기계학습은.. 뭘 이용하셨나요?’
- ‘딥러닝은.. 어떻게 하셨나요?’
저 짧은 질문에선 ‘나도 공부하고 싶은데 아직 방향을 모르겠네요’라는 마음의 소리가 들리는 듯했어요. 저도 저 답답함 속에서 맨땅에 헤딩하는 심정으로 이리저리 정보의 홍수를 탐험하던 때가(아직 진행형일 수 있겠네요.) 있었으니까요. 재미있어서 공부하다가 '내가 파고 있던 우물이 한강이구나'를 느끼면서 뒤를 돌아보는데 우물이 어딨는지 찾고 있는 분들을 보았고 그분들을 위해 이 블로그가 하나의 좌표가 되었으면 합니다.
더 많은 예제도 많겠지만 본 블로그는 AI 공부를 위해 다음과 같은 주제들이 언제 어떻게 쓰이는지를 보여주며 필요성만을 강조하고 싶었어요. 언제 어떻게 쓰이는지 모르는데 하나씩 파고드는 건 괴로운 일이 될 수도 있으니까요! 좋은 사이트 및 레퍼런스를 소개했으니 기계학습과 딥러닝에 입문하시는 분들께 도움되었으면 합니다. 모두 화이팅!!
작성 : Data Science Center 형기은
Posted by 人Co
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/332
Trackback URL : 이 글에는 트랙백을 보낼 수 없습니다

